Dify 是一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流、RAG 管道、Agent、模型管理、可观测性功能等,让您可以快速从原型到生产。
AI+Web3: 从理论到实战的进阶之路
大模型炼成

引用自 https://www.youtube.com/watch?v=bZQun8Y4L2A
预训练的Base model,只能做单词接龙(GPT)或完形填空(Bert)。
监督微调的SFT model,可以称为对话(Chat)模型了。经过少量标注数据进行训练后能适应特定的任务。
与人类价值观对齐的RLHF/DPO model,变得更可用、实用、好用。基于人类反馈强化学习 / 直接偏好优化 与人类价值观对齐,借以生成更精确、真实的回答。
作为固定的“判别器”的RM,参考link。
局限:幻觉;实时知识;复杂推理;私有数据;交互决策;数学(9.9和9.11哪个大);复杂文字逻辑/歧义,等等。所以使用LLM仍要谨慎。
大模型应用
01 提示词工程
情境学习(In Context Learning):提供少量样本示例,Few-shot
思维链(Chain of Thought / CoT)
提示词工程(Prompt Engineering):明确问题、提供上下文、明确期望、人类反馈(多轮对话)、英文提示词
提示词注入/泄露/越狱:比如被问出了windows11专业版的序列号
02 RAG
(Retrieval-Augmented Generation)
1.什么是Embedding/嵌入向量
Embedding是由AI算法生成的高维度的向量数据,代表着数据的不同特征。
在embedding空间中,相似的东西应该“近”,不同的东西应该“远”。embeeding一般是五百至几千道维度,但拿二维来理解的话,远近就类似向量的余弦距离。
语义和语法关系也会被编码到embedding空间中。例如
King - Man + Woman = Queenembedding是一种通用的数据表示方式,各种形式、模态、规模大数据都可以转化为embedding。
2.多模态Embedding
CLIP模型 embedding维度:512,768
收集4亿图像文本对 进行无监督预训练(对比学习)
最大化文本表征和对应图像表征的余弦相似度;最小化文本表征和非对应图像表征的余弦相似度
广泛用于图像分类、图像生成、图像检索、视觉问答等任务
3.RAG的核心思路
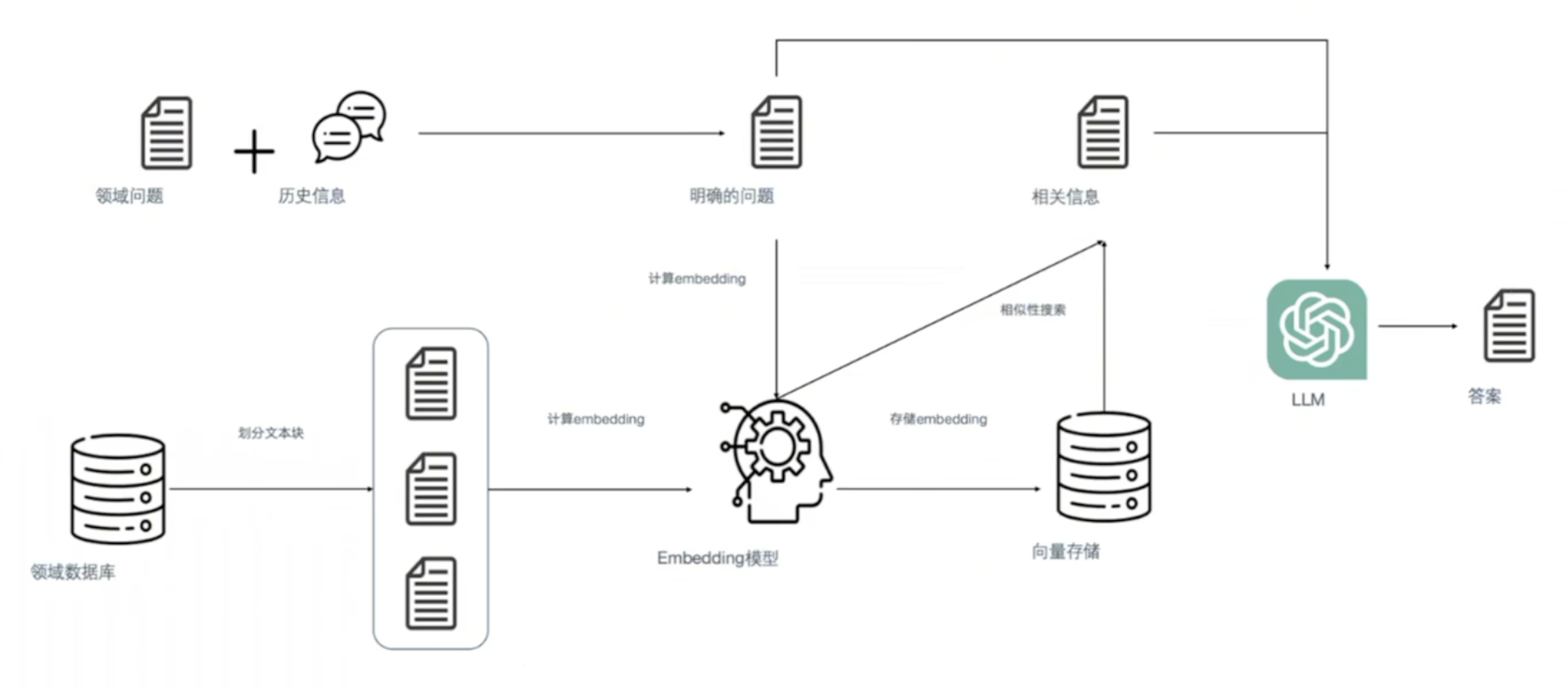
类似于开卷考试。检索出相关信息,和问题一起交给大模型。
03 智能体
智能体Agent的概念,还处于非常早期的阶段。
理想很美好:给出指令,并观察其自动化执行,节约做事的时间成本。
但现实很骨感:生成内容不可靠,过程不稳定,严重依赖人工经验判断。
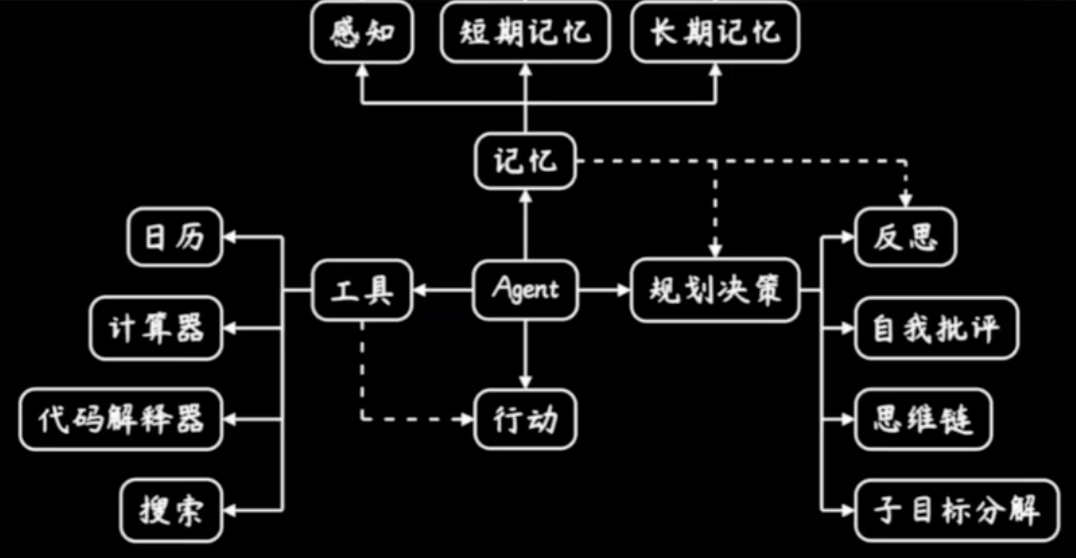
定义:LLM+工具,外部工具(Function Call)实现LLM能力的显式扩展,生成过程可溯源、可解释。
示例:图中有几个穿着红白条纹毛衣的人?
ChatGPT无法完成处理图片,但是通过外接工具,这项任务可以完成。(1) 调用SAM 找到图中所有的人 (2) 调用CLIP判断这些人中哪些符合条件。 并且这些操作由智能体自主进行。
04 大模型的下游任务
例如:文本摘要、文本分类、机器翻译、问答、关系抽取、NL2SQL(自然语言问题转化为SQL查询语句)
对某个下游任务进行针对性微调。
全参数微调(Full Fine-tuning):消耗大量资源,不建议
低资源微调(Parameter Efficient Fine Tuning):有很多方法,其中Lora最为常见。
大模型Agent开发框架
低代码框架:无需代码即可完成Agent开发
Coze(零代码,编排系统基于FlowGram)、Dify(低代码,编排系统基于React Flow)、LangFlow(低代码,LangChain家族的)、FastGPT(开源)
基础框架:借助大模型原生能力进行Agent开发
function calling、tool use
代码框架:借助代码完成Agent开发
LangChain、LangGraph(LangChain家族的,更灵活复杂)、LlamaIndex
Multi-Agent框架/架构:
CrewAI(基于LangChain构建的一个更加上层的框架)、Swarm(轻量、开源,用于教学和实验)、Assistant API(OpenAI的、闭源)、openai-agents(Swarm 的升级版,可投入生产)
热门项目AutoGen、MetaGPT
Coze
Dify
Note
Dify 一词源自 Define + Modify,意指定义并且持续的改进你的 AI 应用,它是为你而做的(Do it for you)。
是一款低代码(low code)生成式AI应用创新引擎。最大的竞品是字节的Coze(扣子)。
Dify官方文档
Dify 是一款开源的低代码LLM应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。
由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
为什么使用 Dify?
LangChain 这类的开发库(Library)想象为有着锤子、钉子的工具箱。与之相比,Dify 好比是一套脚手架,更接近生产需要的完整方案。
Dify 是开源的,由一个专业的全职团队和社区共同打造。在灵活和安全的基础上,同时保持对数据的完全控制。
产品简单、克制、迭代迅速。
Dify 能做什么?
创业,快速的将你的 AI 应用创意变成现实,无论成功和失败都需要加速。在真实世界,已经有几十个团队通过 Dify 构建 MVP(最小可用产品)获得投资,或通过 POC(概念验证)赢得了客户的订单。
将 LLM 集成至已有业务,通过引入 LLM 增强现有应用的能力,接入 Dify 的 RESTful API 从而实现 Prompt 与业务代码的解耦,在 Dify 的管理界面是跟踪数据、成本和用量,持续改进应用效果。
作为企业级 LLM 基础设施,一些银行和大型互联网公司正在将 Dify 部署为企业内的 LLM 网关,加速 GenAI 技术在企业内的推广,并实现中心化的监管。
探索 LLM 的能力边界,即使你是一个技术爱好者,通过 Dify 也可以轻松的实践 Prompt 工程和 Agent 技术。
下一步行动
阅读快速开始,速览 Dify 的应用构建流程
了解如何自部署 Dify 到服务器上,并接入开源模型
了解 Dify 的特性规格和 Roadmap
在 GitHub 上为我们点亮一颗星,并阅读我们的贡献指南
Dify实践
你可以通过 3 种方式在 Dify 的工作室内创建应用:
基于应用模板创建(新手推荐)
创建一个空白应用
通过 DSL 文件(本地/在线)创建应用
Note
Dify DSL 是由 Dify.AI 所定义的 AI 应用工程文件标准,文件格式为 YAML。该标准涵盖应用在 Dify 内的基本描述、模型参数、编排配置等信息。
导入 DSL 文件时将校对文件版本号。如果 DSL 版本号差异较大,有可能会出现兼容性问题。
YAML 曾被称为“Yet Another Markup Language”(又一个标记语言),但后来为了更好地区分其作为数据导向的目的,而重新解释为YAML Ain't Markup Language(回文缩略词)。意味着 YAML 的设计初衷是处理数据,而不是用于文档标记。
聊天助手
对话型应用采用一问一答模式与用户持续对话。
对话型应用的编排支持:对话前提示词,变量,上下文,开场白和下一步问题建议。
Tip
应用工具箱:
对话开场白
下一步问题建议
文字转语音
语音转文字
引用与归属
内容审查
标注回复
多模型调试
你可以同时批量检视不同模型对于相同问题的回答效果。
发布应用
发布为公开Web站点
嵌入网站
基于APIs开发
后端即服务
基于前端组件再开发
WebApp Template,每种类型应用的 WebApp 开发脚手架
智能体
Agent 定义
智能助手(Agent Assistant),利用大语言模型的推理能力,能够自主对复杂的人类任务进行目标规划、任务拆解、工具调用、过程迭代,并在没有人类干预的情况下完成任务。
工作流
工作流通过将复杂的任务分解成较小的步骤(节点)降低系统复杂度,减少了对提示词技术和模型推理能力的依赖,提高了 LLM 应用面向复杂任务的性能,提升了系统的可解释性、稳定性和容错性。
Dify 工作流分为两种类型:
Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
如何开始
从一个空白的工作流开始构建或者使用系统模板帮助你开始;
熟悉基础操作,包括在画布上创建节点、连接和配置节点、调试工作流、查看运行历史等;
保存并发布一个工作流;
在已发布应用中运行或者通过 API 调用工作流;
关键概念
节点:节点是工作流的关键构成,通过连接不同功能的节点,执行工作流的一系列操作。
变量:变量用于串联工作流内前后节点的输入与输出,实现流程中的复杂处理逻辑,包含系统变量、环境变量和会话变量。link
Dify实操
Dify 是一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流、RAG 管道、Agent、模型管理、可观测性功能等,让您可以快速从原型到生产。
启动Dify
cd dify/docker路径下:
启动服务 docker compose up -d
查看容器运行状况 docker compose ps
关闭服务 docker compose down
更新dify
xxxxxxxxxx51cd dify/docker2docker compose down3git pull origin main4docker compose pull5docker compose up -d访问 Dify
你可以先前往管理员初始化页面设置设置管理员账户:
xxxxxxxxxx51# 本地环境2http://localhost/install3
4# 服务器环境5http://your_server_ip/installDify 主页面:
xxxxxxxxxx51# 本地环境2http://localhost3
4# 服务器环境5http://your_server_ip自定义配置
编辑 .env 文件中的环境变量值。然后重新启动 Dify:
xxxxxxxxxx21docker compose down2docker compose up -d完整的环境变量集合可以在 docker/.env.example 中找到。
Swarm to OpenAI-Agents
OpenAI Agents SDK 是一个轻量级但功能强大的框架,用于构建多智能体工作流。
OpenAI Agents SDK 是我们之前针对智能体的实验项目 Swarm 的生产级升级版。
核心概念:
智能体:配置了指令、工具、安全护栏(guardrails)和交接(handoffs)的大语言模型(LLMs)。
交接:Agents SDK 中用于在智能体之间转移控制的专用工具调用。
安全护栏:可配置的安全检查,用于输入和输出的验证。
追踪:内置的智能体运行跟踪,允许您查看、调试和优化工作流。
关于
为什么用Agents SDK
该 SDK 具有两个主要设计原则:
功能足够丰富,值得使用,但基本构件少,便于快速学习。
开箱即用效果很好,但您可以完全自定义具体的操作。
SDK 的主要功能
智能体循环:内置的智能体循环,处理工具调用、将结果发送到语言模型(LLM),并重复执行直到 LLM 完成。
以 Python 为中心:利用内置的语言特性来协调和链接智能体,而不需要学习新的抽象概念。
交接:强大的功能,用于在多个智能体之间协调和委派(delegate)任务。
保护措施:并行运行输入验证和检查,如果检查失败则提前中断。
函数工具:将任何 Python 函数转换为工具,支持自动生成模式和基于 Pydantic 的验证。
追踪:内置的追踪功能,让您可视化、调试和监控工作流,同时使用 OpenAI 的评估、微调和提炼工具套件。
安装
pip install openai-agents
Hello world示例
export OPENAI_API_KEY=sk-...
xxxxxxxxxx101from agents import Agent, Runner2
3agent = Agent(name="Assistant", instructions="You are a helpful assistant")4
5result = Runner.run_sync(agent, "Write a haiku about recursion in programming.")6print(result.final_output)7
8# Code within the code,9# Functions calling themselves,10# Infinite loop's dance.(如果运行此程序,请确保设置 OPENAI_API_KEY 环境变量,参考)
快速开始
x1from agents import Agent, InputGuardrail,GuardrailFunctionOutput, Runner2from pydantic import BaseModel3import asyncio4
5class HomeworkOutput(BaseModel):6 is_homework: bool7 reasoning: str8
9# 护栏智能体10# 我们在护栏函数中使用这个智能体。或许也可以考虑依赖规则的护栏,但那样比较手工,不够智能。11guardrail_agent = Agent(12 name="Guardrail check",13 instructions="Check if the user is asking about homework.",14 output_type=HomeworkOutput,15)16
17# 数学学科-智能体18math_tutor_agent = Agent(19 name="Math Tutor",20 handoff_description="Specialist agent for math questions",21 instructions="You provide help with math problems. Explain your reasoning at each step and include examples",22)23
24# 历史学科-智能体25history_tutor_agent = Agent(26 name="History Tutor",27 handoff_description="Specialist agent for historical questions",28 instructions="You provide assistance with historical queries. Explain important events and context clearly.",29)30
31
32# 护栏33# old version34async def homework_guardrail(ctx, agent, input_data):35 result = await Runner.run(guardrail_agent, input_data, context=ctx.context)36 final_output = result.final_output_as(HomeworkOutput)37 return GuardrailFunctionOutput(38 output_info=final_output,39 tripwire_triggered=not final_output.is_homework,40 )41# new version42async def homework_guardrail( 44 ctx: RunContextWrapper[None], agent: Agent, input: str | list[TResponseInputItem]45) -> GuardrailFunctionOutput:46 result = await Runner.run(guardrail_agent, input, context=ctx.context)47
48 return GuardrailFunctionOutput(49 output_info=result.final_output, tripwire_triggered=not result.final_output.is_homework,50 )51
52
53# 分诊交接54triage_agent = Agent(55 name="Triage Agent",56 instructions="You determine which agent to use based on the user's homework question",57 # 交接是智能体可以委派的子智能体。58 handoffs=[history_tutor_agent, math_tutor_agent],59 input_guardrails=[60 InputGuardrail(guardrail_function=homework_guardrail),61 ],62)63
64# 主函数,先调用预诊交接智能体65async def main():66 result = await Runner.run(triage_agent, "who was the first president of the united states?")67 print(result.final_output)68 69 try:70 result = await Runner.run(triage_agent, "Hello, can you help me solve for x: 2x + 3 = 11?")71 print(result.final_output)72 print("Guardrail didn't trip - this is expected")73 except InputGuardrailTripwireTriggered:74 print("Not related to homework questions guardrail tripped")75 76
77if __name__ == "__main__":78 asyncio.run(main())Note
Agent(name='Math Tutor', instructions='You provide help with math problems. Explain your reasoning at each step and include examples', handoff_description=None, handoffs=[], model=None, model_settings=ModelSettings(temperature=None, top_p=None, frequency_penalty=None, presence_penalty=None, tool_choice=None, parallel_tool_calls=None, truncation=None, max_tokens=None, reasoning=None, metadata=None, store=None), tools=[], mcp_servers=[], mcp_config={}, input_guardrails=[], output_guardrails=[], output_type=None, hooks=None, tool_use_behavior='run_llm_again', reset_tool_choice=True)
xxxxxxxxxx831class Agent(Generic[TContext]):2 """智能体是一个配置了指令、工具、安全护栏、交接等的 AI 模型。3
4 我们强烈建议传递 `instructions`,它是智能体的“系统提示(system prompt)”。此外,你可以传递 `handoff_description`,这是一个人类可读的智能体描述,在智能体被用于工具/交接时使用。5
6 智能体是针对上下文类型的泛型。上下文是你创建的一个(可变)对象。这个上下文会被传递给工具函数、交接、安全护栏等。7 """8
9 name: str10 """智能体的名称。"""11 # 以下是Python的类型注解(type hinting)语法12 instructions: (13 str14 | Callable[15 [RunContextWrapper[TContext], Agent[TContext]],16 MaybeAwaitable[str],17 ]18 | None19 ) = None20 """智能体的指令。当调用此智能体时将作为“系统提示”使用。描述智能体应该做什么,以及它如何回应。21
22 可以是一个字符串,或者是一个动态生成智能体指令的函数。如果提供函数,它将与上下文和智能体实例一起调用。必须返回一个字符串。23 """24
25 handoff_description: str | None = None26 """智能体的描述。当智能体作为交接使用时使用,以便 LLM 知道它的功能以及何时调用它。27 """28
29 handoffs: list[Agent[Any] | Handoff[TContext]] = field(default_factory=list)30 """交接是智能体可以委派的子智能体。你可以提供交接的列表,智能体可以选择在相关时委派它们。允许任务拆解和模块化。31 """32
33 model: str | Model | None = None34 """调用 LLM 时使用的模型实现。35
36 默认情况下,如果未设置,智能体将使用 `model_settings.DEFAULT_MODEL` 中配置的默认模型。37 """38
39 model_settings: ModelSettings = field(default_factory=ModelSettings)40 """配置模型特定的调优参数(例如温度、top_p)。41 """42
43 tools: list[Tool] = field(default_factory=list)44 """智能体可以使用的工具列表。"""45
46 mcp_servers: list[MCPServer] = field(default_factory=list)47 """智能体可以使用的 [模型上下文协议] 服务器列表。每次智能体运行时,它将从这些服务器中包含可用工具的列表。48
49 注意:你需要管理这些服务器的生命周期。具体来说,必须在将其传递给智能体之前调用 `server.connect()`,并在服务器不再需要时调用 `server.cleanup()`。50 """51
52 mcp_config: MCPConfig = field(default_factory=lambda: MCPConfig())53 """MCP 服务器的配置。"""54
55 input_guardrails: list[InputGuardrail[TContext]] = field(default_factory=list)56 """在生成响应之前,智能体执行期间并行运行的检查列表。如果智能体是链中的第一个智能体,则运行。57 """58
59 output_guardrails: list[OutputGuardrail[TContext]] = field(default_factory=list)60 """在生成响应后,对智能体的最终输出进行检查的列表。仅在智能体生成最终输出时运行。61 """62
63 output_type: type[Any] | None = None64 """输出对象的类型。如果未提供,输出将为 `str`。"""65
66 hooks: AgentHooks[TContext] | None = None67 """一个接收各种生命周期事件回调的类,用于此智能体。68 """69
70 tool_use_behavior: (71 Literal["run_llm_again", "stop_on_first_tool"] | StopAtTools | ToolsToFinalOutputFunction72 ) = "run_llm_again"73 """这让你配置工具使用的处理方式。74 - "run_llm_again":默认行为。工具被运行,然后 LLM 收到结果并进行回应。75 - "stop_on_first_tool":第一个工具调用的输出被用作最终输出。这意味着 LLM 不处理工具调用的结果。76 - 工具名称的列表:如果调用列表中的任何工具,智能体将停止运行。最终输出将是第一个匹配工具调用的输出。LLM 不处理工具调用的结果。77 - 函数:如果传递一个函数,它将与运行上下文和工具结果列表一起调用。它必须返回一个 `ToolToFinalOutputResult`,用于确定工具调用是否产生最终输出。78
79 注意:此配置特定于 FunctionTools。托管工具,如文件搜索、网络搜索等,总是由 LLM 处理。80 """81
82 reset_tool_choice: bool = True83 """在调用工具后是否将工具选择重置为默认值。默认为 True。这确保智能体不会进入工具使用的无限循环。"""追踪
要查看智能体运行期间发生的情况,请在 OpenAI 控制面板中导航到追踪查看器,以查看智能体运行的追踪记录。
下一步
了解如何构建更复杂的智能体流程:
了解如何配置智能体。
了解如何运行智能体。
了解工具、安全护栏和模型。
文档
1. 智能体
智能体是你应用中的核心构件。智能体是一个大型语言模型(LLM),经过配置,包含指令和工具。
1.1 泛型
Agent 类,使用了泛型。下面是对这段代码的逐部分解读:
class Agent(Generic[TContext]):
Agent是类的名称。Generic[TContext]表示Agent是一个泛型类,其中TContext是一个类型变量。这个类型变量可以在类的实例化时指定具体类型。
泛型的作用
通过使用 TContext,Agent 类可以与不同类型的上下文(context)配合使用。上下文的类型是泛型的,可以根据需要进行定义。
示例:
xxxxxxxxxx111class UserContext:3 uid: str4 is_pro_user: bool5
6 async def fetch_purchases() -> list[Purchase]:7 return ...8
9agent = Agent[UserContext](10 ...,11)上下文被用作依赖注入工具。这是指上下文可以用于传递所需的依赖项(如配置、服务等)给智能体。
Agents are generic on their
contexttype. Context is a dependency-injection tool: it's an object you create and pass toRunner.run(), that is passed to every agent, tool, handoff etc, and it serves as a grab bag of dependencies and state for the agent run. You can provide any Python object as the context.
1.2 输出类型
默认情况下,智能体生成纯文本(即字符串)输出。如果你希望智能体生成特定类型的输出,可以使用 output_type 参数。常见的选择是使用 Pydantic 对象。
我们支持任何可以被 Pydantic 的 TypeAdapter 包装的类型,如数据类、列表、TypedDict 等。
xxxxxxxxxx131from pydantic import BaseModel2from agents import Agent3
4class CalendarEvent(BaseModel):5 name: str6 date: str7 participants: list[str]8
9agent = Agent(10 name="Calendar extractor",11 instructions="Extract calendar events from text",12 output_type=CalendarEvent,13)Note
当你传递 output_type 时,这告诉模型使用 结构化输出 而不是常规的纯文本响应。
1.3 交接
交接(Handoffs)是智能体可以委托的子智能体。你可以提供一个交接列表,智能体可以在相关时选择委托给它们。这是一种强大的模式,可以协调模块化的、专门化的智能体,使其在单一任务上表现出色。
1.4 动态指令
在大多数情况下,你可以在创建智能体时提供指令。不过,你也可以通过函数提供动态指令。该函数将接收智能体和上下文,并必须返回提示。使用常规函数和异步函数都被允许。
xxxxxxxxxx101def dynamic_instructions(2 context: RunContextWrapper[UserContext], agent: Agent[UserContext]3) -> str:4 return f"The user's name is {context.context.name}. Help them with their questions."5
6
7agent = Agent[UserContext](8 name="Triage agent",9 instructions=dynamic_instructions,10)1.5 生命周期事件(钩子)
有时,你可能想观察智能体的生命周期。例如,你可能希望在某些事件发生时记录事件或预取数据。你可以通过 hooks 属性挂钩到智能体生命周期。通过子类化 AgentHooks 类,并重写你感兴趣的方法。
1.6 护栏
护栏(Guardrails)允许你在智能体运行的同时,对用户输入进行检查和验证。例如,你可以筛选用户的输入以判断其相关性。
1.7 复制智能体
通过在智能体上使用 clone() 方法,你可以复制一个智能体,并可以选择更改任何属性。
xxxxxxxxxx111# 海盗2pirate_agent = Agent(3 name="Pirate",4 instructions="Write like a pirate",5 model="o3-mini",6)7# 机器人8robot_agent = pirate_agent.clone(9 name="Robot",10 instructions="Write like a robot",11)1.8 强制使用工具
提供工具列表并不总意味着 LLM 会使用某个工具。你可以通过设置 ModelSettings.tool_choice 来强制使用工具。有效值包括:
auto:允许 LLM 决定是否使用工具。
required:要求 LLM 使用工具(但可以智能地决定使用哪个工具)。
none:要求 LLM 不使用任何工具。
设置特定字符串,例如
my_tool,要求 LLM 使用该特定工具。
Note
为了防止无限循环,框架在每次工具调用后会自动将 tool_choice 重置为 "auto"。此行为可以通过 agent.reset_tool_choice 进行配置。无限循环的原因是工具结果会被发送给 LLM,随后 LLM 可能会生成另一个工具调用,从而导致无限循环。
如果你希望智能体在工具调用后完全停止(而不是继续使用自动模式),可以设置 Agent.tool_use_behavior="stop_on_first_tool",这将直接使用工具输出作为最终响应,而不进行进一步的 LLM 处理。
2. 运行智能体
你可以通过 Runner 类运行智能体,有三种选项:
Runner.run():异步运行并返回RunResult。Runner.run_sync():同步方法,实质上运行run()。Runner.run_streamed():异步运行并返回RunResultStreaming。它以流式模式调用 LLM,并在接收事件时将其流式传输给你。
2.1 智能体循环
当你在 Runner 中使用 run 方法时,你需要传入一个起始智能体和输入。输入可以是一个字符串(视为用户消息),也可以是一个输入项的列表。
Runner 会运行一个循环:
调用当前智能体的 LLM,使用当前输入。
LLM 生成输出。
如果 LLM 返回
final_output,循环结束,我们返回结果。如果 LLM 进行移交(handoff),我们更新当前智能体和输入,并重新运行循环。
如果 LLM 产生工具调用,我们执行这些工具调用,附加结果,并重新运行循环。
如果超过传入的
max_turns,则引发MaxTurnsExceeded异常。
Note
判断 LLM 输出是否被视为final_output的规则是:它生成了符合所需类型的文本输出,且没有工具调用。
2.2 流式
2.3 运行配置
run_config 参数让你可以配置一些全局设置以供智能体运行使用:
model:允许设置全局 LLM 模型,与每个智能体的模型无关。
model_provider:用于查找模型名称的模型提供者,默认为 OpenAI。
model_settings:覆盖特定于智能体的设置。例如,可以设置全局的温度或
top_p。input_guardrails, output_guardrails:在所有运行中包含的输入或输出护栏。
handoff_input_filter:应用于所有移交的全局输入过滤器(如果移交中尚未有过滤器)。输入过滤器允许你编辑发送给新智能体的输入。有关更多详细信息,请参见
Handoff.input_filter的文档。tracing_disabled:允许禁用整个运行的追踪。
trace_include_sensitive_data:配置追踪是否会包括潜在的敏感数据,例如 LLM 和工具调用的输入/输出。
workflow_name, trace_id, group_id:设置运行的追踪工作流名称、追踪 ID 和追踪组 ID。我们建议至少设置
workflow_name。组 ID 是一个可选字段,允许你在多个运行之间链接追踪。
trace_metadata:要包含在所有追踪中的元数据。
2.4 对话/聊天线程
调用任何 run 方法可能会导致一个或多个智能体运行(因此会有一个或多个 LLM 调用),但这代表了聊天对话中的一个逻辑轮次。例如:
用户轮次:用户输入文本。
Runner 运行:第一个智能体调用 LLM,运行工具,移交给第二个智能体,第二个智能体运行更多工具,然后生成输出。
在智能体运行结束时,你可以选择向用户展示什么内容。例如,你可以展示智能体生成的每个新项,或者仅展示最终输出。无论哪种情况,用户可能会问后续问题,此时你可以再次调用 run 方法。
你可以使用 RunResultBase.to_input_list() 方法获取下一个轮次的输入。
xxxxxxxxxx141async def main():2 agent = Agent(name="Assistant", instructions="Reply very concisely.")3
4 with trace(workflow_name="Conversation", group_id=thread_id):5 # First turn6 result = await Runner.run(agent, "What city is the Golden Gate Bridge in?")7 print(result.final_output)8 # San Francisco9
10 # Second turn11 new_input = result.to_input_list() + [{"role": "user", "content": "What state is it in?"}]12 result = await Runner.run(agent, new_input)13 print(result.final_output)14 # California2.5 异常
SDK 在某些情况下会引发异常。完整列表见 agents.exceptions。以下是概述:
AgentsException:SDK 中所有异常的基类。
MaxTurnsExceeded:当运行超过传入的
max_turns时引发。ModelBehaviorError:当模型生成无效输出时引发,例如格式错误的 JSON 或使用不存在的工具。
UserError:当你(使用 SDK 编写代码的人)在使用 SDK 时发生错误时引发。
InputGuardrailTripwireTriggered 和 OutputGuardrailTripwireTriggered:当保护措施被触发时引发。
3. 结果
当你调用 Runner.run 方法时,你会获得以下其中之一:
RunResult:如果你调用
run或run_sync。RunResultStreaming:如果你调用
run_streamed。
这两者都继承自 RunResultBase,其中包含大多数有用的信息。
3.1 最终输出
final_output 属性包含最后运行的智能体的最终输出。为以下两种情况之一:
如果最后的智能体没有定义
output_type,则为str。如果智能体定义了输出类型,则为类型
last_agent.output_type的对象。
Note
final_output 的类型为 Any。我们无法静态类型化它,因为在移交时,最后的智能体可能是任何一个,因此我们无法静态确定可能的输出类型集合。
3.2 下一轮次的输入
你可以使用 result.to_input_list() 方法将结果转换为输入列表,该列表将你提供的原始输入与智能体运行期间生成的项连接起来。这使得将一个智能体运行的输出传递到另一个运行中变得方便,或者在循环中运行并每次附加新的用户输入。
3.3 最后智能体
last_agent 属性包含最后运行的智能体。根据你的应用情况,这通常在用户下次输入时很有用。例如,如果你有一个分诊智能体,它会移交给特定语言的智能体,你可以存储最后的智能体,并在用户下次消息时重用它。
3.4 新项
new_items 属性包含在运行期间生成的新项。这些项是 RunItems,每个项封装了 LLM 生成的原始项。
MessageOutputItem:表示 LLM 生成的消息。原始项是具体的消息内容。
HandoffCallItem:表示 LLM 调用了移交工具。原始项是发起的工具调用信息。
HandoffOutputItem:表示发生了移交,原始项是移交工具的响应。此项也可以访问交接的源/目标智能体的信息。
ToolCallItem:表示 LLM 调用了一个工具,记录了调用的动作。
ToolCallOutputItem:表示工具被调用后的响应,包含工具的输出。
ReasoningItem:表示 LLM 生成的推理结果,记录了其推理过程。
3.5 其他信息
Guardrail 结果:
input_guardrail_results和output_guardrail_results包含 guardrails 的结果,可能包含有用的信息,开发者可以选择记录或存储。
原始响应:
raw_responses包含 LLM 生成的具体输出ModelResponses。
原始输入:
input属性包含你提供的原始输入,通常不需要,但可以在特定情况下使用。
4. 流式
流式处理允许你在智能体运行过程中订阅更新。这对于向最终用户显示进度更新和部分响应非常有用。
4.1 原始响应事件
RawResponsesStreamEvent 是直接从 LLM 传递的原始事件,采用 OpenAI Responses API 格式。每个事件都有一个类型(如 response.created、response.output_text.delta 等)和数据。
这些事件在你希望实时向用户传输生成的响应消息时非常有用。
xxxxxxxxxx211'''2示例:逐个 Token 输出 LLM 生成的文本,实时反馈用户所需的信息。3'''4import asyncio5from openai.types.responses import ResponseTextDeltaEvent6from agents import Agent, Runner7
8async def main():9 agent = Agent(10 name="Joker",11 instructions="You are a helpful assistant.",12 )13
14 result = Runner.run_streamed(agent, input="Please tell me 5 jokes.")15 async for event in result.stream_events():16 if event.type == "raw_response_event" and isinstance(event.data, ResponseTextDeltaEvent):17 print(event.data.delta, end="", flush=True)18
19
20if __name__ == "__main__":21 asyncio.run(main())4.2 运行项事件和智能体事件
RunItemStreamEvents 是更高级的事件,通知你某个项目已完全生成。这使你能够在“消息生成”、“工具运行”等级别推送进度更新,而不是逐个 Token。同样,AgentUpdatedStreamEvent 在当前智能体发生变化时提供更新(例如,因交接而变化)。
xxxxxxxxxx491'''2示例:通过使用这些事件,可以忽略原始事件,向用户流式传输更新。3'''4import asyncio5import random6from agents import Agent, ItemHelpers, Runner, function_tool7
8def how_many_jokes() -> int:10 return random.randint(1, 10)11
12
13async def main():14 agent = Agent(15 name="Joker",16 instructions="First call the `how_many_jokes` tool, then tell that many jokes.",17 tools=[how_many_jokes],18 )19
20 result = Runner.run_streamed(21 agent,22 input="Hello",23 )24 print("=== Run starting ===")25
26 async for event in result.stream_events():27 # We'll ignore the raw responses event deltas28 if event.type == "raw_response_event":29 continue30 # When the agent updates, print that31 elif event.type == "agent_updated_stream_event":32 print(f"Agent updated: {event.new_agent.name}")33 continue34 # When items are generated, print them35 elif event.type == "run_item_stream_event":36 if event.item.type == "tool_call_item":37 print("-- Tool was called")38 elif event.item.type == "tool_call_output_item":39 print(f"-- Tool output: {event.item.output}")40 elif event.item.type == "message_output_item":41 print(f"-- Message output:\n {ItemHelpers.text_message_output(event.item)}")42 else:43 pass # Ignore other event types44
45 print("=== Run complete ===")46
47
48if __name__ == "__main__":49 asyncio.run(main())5. 工具
工具使智能体能够执行各种操作,例如获取数据、运行代码、调用外部 API,甚至使用计算机。在 Agent SDK 中有三类工具:
托管工具:这些工具在 LLM 服务器上与 AI 模型一起运行。OpenAI 提供检索、网页搜索和计算机使用作为托管工具。
函数调用:允许你将任何 Python 函数用作工具。
智能体作为工具:这允许你将智能体作为工具使用,使智能体能够调用其他智能体,而无需进行交接。
5.1 托管工具
OpenAI 在使用 OpenAIResponsesModel 时提供了一些内置工具:
WebSearchTool:允许智能体在网上搜索信息。
FileSearchTool:允许从你的 OpenAI 向量存储中检索信息。
ComputerTool:允许自动化计算机使用任务。
xxxxxxxxxx161from agents import Agent, FileSearchTool, Runner, WebSearchTool2
3agent = Agent(4 name="Assistant",5 tools=[6 WebSearchTool(),7 FileSearchTool(8 max_num_results=3,9 vector_store_ids=["VECTOR_STORE_ID"],10 ),11 ],12)13
14async def main():15 result = await Runner.run(agent, "Which coffee shop should I go to, taking into account my preferences and the weather today in SF?")16 print(result.final_output)5.2 函数工具
你可以将任何 Python 函数用作工具。Agents SDK 会自动设置工具:
工具名称将是 Python 函数的名称(或你可以提供一个名称)。
工具描述将来自函数的文档字符串(或你可以提供描述)。
函数输入的 schema 会根据函数的参数自动创建。
每个输入的描述来自函数的文档字符串,除非被禁用。
我们使用 Python 的 inspect 模块提取函数签名,并使用 griffe 解析文档字符串,使用 pydantic 进行 schema 创建。
xxxxxxxxxx461import json2
3from typing_extensions import TypedDict, Any4
5from agents import Agent, FunctionTool, RunContextWrapper, function_tool6
7
8class Location(TypedDict):9 lat: float # 纬度10 long: float # 经度11
12 13async def fetch_weather(location: Location) -> str:14 15 """Fetch the weather for a given location.16
17 Args:18 location: The location to fetch the weather for.19 """20 # In real life, we'd fetch the weather from a weather API21 return "sunny"22
23
24(name_override="fetch_data") 25def read_file(ctx: RunContextWrapper[Any], path: str, directory: str | None = None) -> str:26 """Read the contents of a file.27
28 Args:29 path: The path to the file to read.30 directory: The directory to read the file from.31 """32 # In real life, we'd read the file from the file system33 return "<file contents>"34
35
36agent = Agent(37 name="Assistant",38 tools=[fetch_weather, read_file], 39)40
41for tool in agent.tools:42 if isinstance(tool, FunctionTool):43 print(tool.name)44 print(tool.description)45 print(json.dumps(tool.params_json_schema, indent=2))46 print()5.3 智能体作为工具
在某些工作流中,您可能希望有一个中央智能体来协调一组专业智能体,而不是进行控制交接。您可以通过将智能体建模为工具来实现这一点。
xxxxxxxxxx341from agents import Agent, Runner2import asyncio3
4spanish_agent = Agent(5 name="Spanish agent",6 instructions="You translate the user's message to Spanish",7)8
9french_agent = Agent(10 name="French agent",11 instructions="You translate the user's message to French",12)13
14orchestrator_agent = Agent(15 name="orchestrator_agent",16 instructions=(17 "You are a translation agent. You use the tools given to you to translate."18 "If asked for multiple translations, you call the relevant tools."19 ),20 tools=[21 spanish_agent.as_tool(22 tool_name="translate_to_spanish",23 tool_description="Translate the user's message to Spanish",24 ),25 french_agent.as_tool(26 tool_name="translate_to_french",27 tool_description="Translate the user's message to French",28 ),29 ],30)31
32async def main():33 result = await Runner.run(orchestrator_agent, input="Say 'Hello, how are you?' in Spanish.")34 print(result.final_output)5.4 在函数工具中处理错误
当您通过 @function_tool 创建一个函数工具时,可以传递 failure_error_function。这是一个在工具调用崩溃时向 LLM 提供错误响应的函数。
默认行为:如果您不传递任何内容,它会运行
default_tool_error_function,通知 LLM 发生了错误。自定义错误函数:如果您传递自己的错误函数,它将运行该函数,并将响应发送给 LLM。
显式传递 None:如果您显式传递
None,则任何工具调用错误将被重新引发,供您处理。这可能是ModelBehaviorError(如果模型生成了无效的 JSON),或UserError(如果您的代码崩溃)等。
如果您手动创建 FunctionTool 对象,则必须在 on_invoke_tool 函数内处理错误。
6. 模型上下文协议 (MCP)
模型上下文协议(MCP)是一种为 LLM 提供工具和上下文的方法。根据 MCP 文档:
Note
MCP 是一个开放协议,标准化了应用程序向 LLM 提供上下文的方式。可以将 MCP 类比于 AI 应用的 USB-C 接口。正如 USB-C 为设备连接各种外设和配件提供了标准化的方式,MCP 也为 AI 模型连接不同的数据源和工具提供了标准化的方式。
Agents SDK 支持 MCP。这使您能够使用广泛的 MCP 服务器为您的智能体提供工具。
6.1 MCP 服务器
目前,MCP 规范定义了两种类型的服务器,基于它们使用的传输机制:
标准输入输出 (stdio) 服务器:作为应用程序的子进程运行,可以视为“本地”运行。
HTTP over SSE 服务器:远程运行,通过 URL 连接。
您可以使用 MCPServerStdio 和 MCPServerSse 类来连接这些服务器。
以下是一个简单的示例,演示如何使用官方 MCP 文件系统服务器:
xxxxxxxxxx81# async,在等待 server.list_tools() 完成时,不会阻塞程序的其他部分。2async with MCPServerStdio(3 params={4 "command": "npx",5 "args": ["-y", "@modelcontextprotocol/server-filesystem", samples_dir],6 }7) as server:8 tools = await server.list_tools()6.2 使用 MCP 服务器
MCP 服务器可以添加到智能体中。每次运行智能体时,Agents SDK 将调用 MCP 服务器上的 list_tools()。这使得 LLM 了解 MCP 服务器的工具。当 LLM 调用 MCP 服务器上的工具时,SDK 会在该服务器上调用 call_tool()。
xxxxxxxxxx51agent=Agent(2 name="Assistant",3 instructions="Use the tools to achieve the task",4 mcp_servers=[mcp_server_1, mcp_server_2]5)6.3 缓存
每次智能体运行时,它都会在 MCP 服务器上调用 list_tools()。这可能会导致延迟,尤其是当服务器是远程服务器时。为了自动缓存工具列表,可以将 cache_tools_list=True 传递给 MCPServerStdio 和 MCPServerSse。您只有在确定工具列表不会更改时才应这样做。
如果您想使缓存失效,可以在服务器上调用 invalidate_tools_cache()。
可在 example/mcp 查看完整的工作示例。
6.4 跟踪
跟踪功能会自动捕获 MCP 操作,包括:
MCP 服务器的
list_tools()的调用与 MCP 相关的函数调用信息
7. 交接
交接允许一个智能体将任务委托给另一个智能体。这在不同智能体专注于不同领域的场景中尤其有用。例如,一个客户支持的app可能有专门处理订单状态、退款、FAQ等任务的智能体。
交接被表示为 LLM 的工具。因此,如果有一个交接给名为“Refund(退款) Agent”的智能体,则该工具将被称为 transfer_to_refund_agent。
7.1 创建交接
所有智能体都有一个 handoffs 参数,该参数可以直接接受一个智能体,或接受一个自定义的 Handoff 对象。
您可以使用 Agents SDK 提供的 handoff() 函数创建任务移交。这个函数允许您指定要移交的智能体,并提供可选的覆盖和输入过滤器。
xxxxxxxxxx71from agents import Agent, handoff2
3billing_agent = Agent(name="Billing agent")4refund_agent = Agent(name="Refund agent")5
6# 您可以直接使用智能体(例如 billing_agent),或者使用 handoff() 函数进行任务移交。7triage_agent = Agent(name="Triage agent", handoffs=[billing_agent, handoff(refund_agent)])7.2 通过 handoff() 函数自定义交接
handoff() 函数允许您自定义以下内容:
agent: 这是将要移交任务的智能体。
tool_name_override: 默认情况下,使用
Handoff.default_tool_name()函数,它解析为transfer_to_<agent_name>。您可以对此进行覆盖。tool_description_override: 覆盖
Handoff.default_tool_description()的默认工具描述。on_handoff: 在移交被调用时执行的回调函数。这对于在知道移交被触发时立即开始数据获取等操作非常有用。此函数接收智能体上下文,并可以选择性地接收 LLM 生成的输入。输入数据由
input_type参数控制。input_type: 移交所期望的输入类型(可选)。
input_filter: 允许您过滤下一个智能体接收到的输入。有关更多信息,请参见下文。
xxxxxxxxxx131from agents import Agent, handoff, RunContextWrapper2
3def on_handoff(ctx: RunContextWrapper[None]):4 print("Handoff called")5
6agent = Agent(name="My agent")7
8handoff_obj = handoff(9 agent=agent,10 on_handoff=on_handoff,11 tool_name_override="custom_handoff_tool",12 tool_description_override="Custom description",13)7.3 交接输入
在某些情况下,您希望 LLM 在调用移交时提供一些数据。例如,想象一下移交给“向上反映(Escalation)智能体”。您可能希望提供一个原因,以便进行记录。
通过在 handoff() 函数中使用适当的参数,您可以指定所需的输入数据,从而确保在移交时传递必要的信息。
xxxxxxxxxx171from pydantic import BaseModel2
3from agents import Agent, handoff, RunContextWrapper4
5class EscalationData(BaseModel):6 reason: str7
8async def on_handoff(ctx: RunContextWrapper[None], input_data: EscalationData):9 print(f"Escalation agent called with reason: {input_data.reason}")10
11agent = Agent(name="Escalation agent")12
13handoff_obj = handoff(14 agent=agent,15 on_handoff=on_handoff,16 input_type=EscalationData,17)7.4 输入过滤器
当发生移交时,新的智能体会接管对话,并能够看到整个之前的对话历史。如果您想更改这一点,可以设置一个输入过滤器。
输入过滤器是一个接收现有输入的函数,通过 HandoffInputData 传递,并必须返回一个新的 HandoffInputData。
一些常见的模式(例如从历史记录中移除所有工具调用)已经在 agents.extensions.handoff_filters 中为您实现。这样,您可以轻松地应用这些标准过滤器,或根据需要自定义自己的过滤器。
xxxxxxxxxx91from agents import Agent, handoff2from agents.extensions import handoff_filters3
4agent = Agent(name="FAQ agent")5
6handoff_obj = handoff(7 agent=agent,8 input_filter=handoff_filters.remove_all_tools, 9)7.5 推荐提示词
为了确保 LLM 正确理解任务移交,我们建议在您的智能体中包含有关移交的信息。我们提供了一个建议的前缀,您可以在 agents.extensions.handoff_prompt.RECOMMENDED_PROMPT_PREFIX 中找到,或者可以调用 agents.extensions.handoff_prompt.prompt_with_handoff_instructions 来自动将推荐数据添加到您的提示中。
通过这些方法,您可以增强智能体对移交的理解,确保更顺畅的任务转移。
xxxxxxxxxx91from agents import Agent2from agents.extensions.handoff_prompt import RECOMMENDED_PROMPT_PREFIX3
4# 在 Python 中,使用三重引号(""" 或 ''')可以定义多行字符串5billing_agent = Agent(6 name="Billing agent",7 instructions=f"""{RECOMMENDED_PROMPT_PREFIX}8 <Fill in the rest of your prompt here>.""",9)8. 追踪
Agents SDK 包含内置追踪功能,可以全面记录智能体运行期间的事件,包括:LLM 生成、工具调用、任务移交、保护措施,以及发生的自定义事件。使用 Traces dashboard,您可以在开发和生产过程中调试、可视化和监控您的工作流程。
8.1 追踪和跨度
追踪代表一个“工作流”的单一端到端操作,由多个 跨度 组成。追踪具有以下属性:
workflow_name: 这是逻辑工作流或应用的名称,例如“代码生成”或“客户服务”。
trace_id: 追踪的唯一 ID。如果您不传递,则自动生成。格式必须为
trace_<32_alphanumeric>。group_id: 可选的组 ID,用于链接来自同一对话的多个追踪。例如,您可以使用聊天线程 ID。
disabled: 如果为 True,则该追踪不会被记录。
metadata: 可选的追踪元数据。
跨度代表具有开始和结束时间的操作。跨度具有以下属性:
started_at 和 ended_at 时间戳。
trace_id: 表示它所属的追踪。
parent_id: 指向该跨度的父跨度(如果有)。
span_data: 有关跨度的信息。例如,
AgentSpanData包含有关智能体的信息,GenerationSpanData包含有关 LLM 生成的信息等。
8.2 默认追踪
默认情况下,SDK 会追踪以下内容:
整个
Runner.{run, run_sync, run_streamed}()被封装在trace()中。每次智能体运行时,被封装在
agent_span()中。LLM 生成被封装在
generation_span()中。函数工具调用被分别封装在
function_span()中。保护措施被封装在
guardrail_span()中。任务移交被封装在
handoff_span()中。音频输入(语音转文本)被封装在
transcription_span()中。音频输出(文本转语音)被封装在
speech_span()中。相关的音频跨度可能被归类为
speech_group_span()的子跨度。
默认情况下,追踪命名为“Agent trace”。如果您使用 trace,可以设置此名称,或者可以通过 RunConfig 配置名称及其他属性。
此外,您可以设置自定义追踪处理器,将追踪推送到其他目标(作为替代或次要目标)。
8.3 更高层次的追踪
有时,您可能希望将多个 run() 调用作为单个追踪的一部分。您可以通过将整个代码块封装在 trace() 中来实现这一点。这样,所有包含的操作都将被记录为同一个追踪,提高了整体监控的连贯性。
xxxxxxxxxx101from agents import Agent, Runner, trace2
3async def main():4 agent = Agent(name="Joke generator", instructions="Tell funny jokes.")5
6 with trace("Joke workflow"): 7 first_result = await Runner.run(agent, "Tell me a joke")8 second_result = await Runner.run(agent, f"Rate this joke: {first_result.final_output}")9 print(f"Joke: {first_result.final_output}")10 print(f"Rating: {second_result.final_output}")8.4 创建追踪
您可以使用 trace() 函数来创建追踪。追踪需要启动和结束,您有两种选择:
推荐方式: 将
trace用作上下文管理器,例如with trace(...) as my_trace。这将自动在正确的时间启动和结束追踪。手动方式: 您也可以手动调用
trace.start()和trace.finish()。
当前追踪通过 Python 的 contextvar 进行跟踪,这意味着它会自动处理并发。如果您手动启动/结束追踪,您需要在 start()/finish() 中传递 mark_as_current 和 reset_current 以更新当前追踪。
8.5 创建跨度
您可以使用各种 *_span() 方法来创建跨度。通常情况下,您不需要手动创建跨度。
8.6 敏感数据
某些跨度可能会捕获潜在的敏感数据。
generation_span()存储 LLM 生成的输入/输出,而function_span()存储函数调用的输入/输出。这些可能包含敏感数据,因此您可以通过RunConfig.trace_include_sensitive_data禁用捕获这些数据。同样,音频跨度默认包括输入和输出音频的 base64 编码 PCM 数据。您可以通过配置
VoicePipelineConfig.trace_include_sensitive_audio_data来禁用捕获这些音频数据。
8.7 自定义追踪处理器
追踪的高层架构如下:
初始化时,我们创建一个全局
TraceProvider,负责创建追踪。我们使用
BatchTraceProcessor配置TraceProvider,该处理器将追踪/跨度批量发送到BackendSpanExporter,后者将这些跨度和追踪批量导出到 OpenAI 后端。
要自定义此默认设置,以将追踪发送到替代或附加后端或修改导出器行为,您有两个选项:
add_trace_processor()允许您添加一个额外的追踪处理器,该处理器将在追踪和跨度准备好时接收它们。这使您可以进行自定义处理,除了将追踪发送到 OpenAI 的后端。set_trace_processors()允许您用自己的追踪处理器替换默认处理器。这意味着追踪不会发送到 OpenAI 后端,除非您包含一个执行此操作的TracingProcessor。
8.8 外部追踪处理器列表
9. 上下文管理
“上下文”是一个多义词。您可能关心的主要有两类上下文:
本地上下文:这是您的代码在工具函数运行时、回调(如
on_handoff)、生命周期钩子等情况下可能需要的数据和依赖项。LLM 上下文:这是 LLM 在生成响应时所看到的数据。
这两类上下文在不同的场景中发挥着关键作用。
9.1 本地上下文
本地上下文通过 RunContextWrapper 类及其中的 context 属性表示。其工作原理如下:
创建任意 Python 对象。常见的模式是使用数据类(dataclass)或 Pydantic 对象。
将该对象传递给各种运行方法(例如
Runner.run(..., **context=whatever**))。所有的工具调用、生命周期钩子等将接收一个包装对象
RunContextWrapper[T],其中 T 代表您的上下文对象类型,可以通过wrapper.context访问。
需要注意的最重要一点是:对于给定的智能体运行,每个智能体、工具函数和生命周期等必须使用相同类型的上下文。
您可以利用上下文进行以下操作:
运行的上下文数据(例如用户名、用户 ID 或其他用户信息)
依赖项(例如日志记录对象、数据获取器等)
辅助函数
Note
上下文对象不会被发送到 LLM。它纯粹是一个本地对象,您可以从中读取、写入并调用其方法。
xxxxxxxxxx351import asyncio2from dataclasses import dataclass3
4from agents import Agent, RunContextWrapper, Runner, function_tool5
6class UserInfo: 8 name: str9 uid: int10
11async def fetch_user_age(wrapper: RunContextWrapper[UserInfo]) -> str: 13 return f"User {wrapper.context.name} is 47 years old"14
15async def main():16 user_info = UserInfo(name="John", uid=123)17 # 我们用泛型UserInfo标记智能体,以便类型检查器能够捕获错误。例如,如果我们试图传递一个接受不同上下文类型的工具,类型检查器将会报错。这样可以确保上下文的一致性和正确性。18
19 agent = Agent[UserInfo]( 20 name="Assistant",21 tools=[fetch_user_age],22 )23
24 result = await Runner.run( 25 starting_agent=agent,26 input="What is the age of the user?",27 # 上下文会传递给运行函数28 context=user_info,29 )30
31 print(result.final_output) 32 # The user John is 47 years old.33
34if __name__ == "__main__":35 asyncio.run(main())9.2智能体/LLM 上下文
当调用 LLM 时,它只能看到对话历史中的数据。这意味着如果要向 LLM 提供新数据,必须以可以在历史中访问的方式进行。以下是几种方法:
添加到智能体指令:这称为“系统提示”或“开发者消息”。系统提示可以是静态字符串,也可以是接收上下文并输出字符串的动态函数。这对于始终有用的信息(例如用户名或当前日期)是常见的策略。
在调用
Runner.run函数时添加输入通过工具函数暴露:适用于按需上下文,LLM 根据需要调用工具以获取数据。
使用检索或网络搜索:这些特殊工具能够从文件或数据库(检索)或从网络(网络搜索)中获取相关数据。比如RAG。
10. 护栏
护栏与智能体同时运行,可以对用户输入进行检查和验证。
例如,假设你有一个使用非常智能(因此较慢/昂贵)模型来处理客户请求的智能体。你不希望恶意用户请求模型帮助他们做数学作业。因此,你可以使用一个快速/便宜的模型来运行护栏。如果护栏检测到恶意使用,它可以立即引发错误,阻止昂贵模型的运行,从而节省时间和金钱。
保护机制有两种类型:
输入保护机制:作用于用户初始输入
输出保护机制:作用于智能体最终输出
10.1 输入护栏
输入护栏分为三步:
首先,护栏接收传递给智能体的相同输入。
接下来,护栏函数运行,得到一个
GuardrailFunctionOutput,并将其封装在InputGuardrailResult中。最后,我们检查
.tripwire_triggered是否为真。如果为真,则会引发InputGuardrailTripwireTriggered异常,以便您可以适当地响应用户或处理该异常。
Tip
输入护栏旨在处理用户输入,因此智能体的护栏仅在其为第一个智能体时运行。你可能会问,为什么输入护栏属性在智能体上,而不是传递给 Runner.run?
这是因为护栏通常与实际智能体相关——不同的智能体会运行不同的护栏,因此将代码放在一起有助于提高可读性。
输出护栏同理。
10.2 输出护栏
输出护栏也分为三步:
首先,护栏接收传递给智能体的相同输入。
接下来,护栏函数运行,生成一个
GuardrailFunctionOutput,并将其封装在OutputGuardrailResult中。最后,我们检查
.tripwire_triggered是否为真。如果为真,则会引发OutputGuardrailTripwireTriggered异常,以便您可以适当地响应用户或处理该异常。
10.3 触发器
tripwire | BrE ˈtrɪpˌwʌɪə, AmE ˈtrɪpˌwaɪ(ə)r | noun (working a trap) 绊脚线; (setting off an explosion) 触发线; (working an alarm) 拉发线; (in computing context) 触发器
如果输入或输出未通过护栏,护栏可以通过触发器发出信号。一旦我们检测到,就会立即引发 {Input,Output}GuardrailTripwireTriggered 异常,并停止智能体的执行。
Tip
输入护栏的示例可参考 - 快速开始 -,输出护栏是类似的。
11. 协调多个智能体
协调指的是应用中智能体的流动。哪些智能体运行,顺序如何,以及它们如何决定接下来发生什么?协调智能体主要有两种方式:
允许LLM做决定:利用LLM的智能来规划、推理和决定采取哪些步骤。
通过代码协调:通过代码确定智能体的流动。
你可以混合使用这些模式。每种方式都有其优缺点,下面进行描述。
11.1 通过LLM协调
智能体是一个配备了指令、工具和移交机制的LLM。这意味着在面对开放性任务时,LLM可以自主规划如何处理任务,利用工具采取行动和获取数据,并通过移交将任务委派给子智能体。例如,一个研究智能体可以配备以下工具:
网络搜索:在线查找信息
文件搜索和检索:搜索专有数据和连接
计算机使用:在计算机上采取行动
代码执行:进行数据分析
移交:给擅长规划、报告写作等的专业智能体
这种模式在开放性任务里非常有效,尤其是在希望依赖LLM智能的情况下。这里最重要的策略包括:
投资于良好的提示:清楚说明哪些工具可用、如何使用它们以及必须遵循的参数。
监控应用并进行迭代:查看问题出现的地方,并对提示进行迭代。
允许智能体自我反思和改进:例如,循环运行,让它自我批评;或者提供错误信息,让它进行改进。
拥有擅长单一任务的专业智能体,而不是期待通用智能体在任何任务上都表现良好。
投资评估:这让你可以训练智能体,帮助它们在任务中不断提升。
11.2 通过代码协调
虽然通过LLM协调非常强大,但通过代码协调使任务在速度、成本和效果方面更加确定和可预测。常见模式包括:
使用结构化输出:生成可以通过代码检查的格式良好的数据。例如,可以要求智能体将任务分类为几个类别,然后根据类别选择下一个智能体。
Tip
JSON 是世界上应用程序交换数据最广泛使用的格式之一。
结构化输出 是一项功能,它能确保模型始终生成符合您提供的 JSON Schema 的响应,因此您无需担心模型遗漏必要键值、或生成无效的枚举值。
结构化输出的优势包括:
可靠的类型安全 无需验证或重试格式错误的响应
显式拒绝机制 基于安全策略的模型拒绝行为可通过编程方式检测
更简洁的提示设计 无需使用强约束性提示词即可实现一致的格式输出
链式多个智能体:将一个智能体的输出转化为下一个智能体的输入。可以将写博客文章的任务分解为一系列步骤——进行研究、写提纲、撰写博客文章、进行批评,然后改进。
在循环中运行执行任务的智能体:与评估并提供反馈的智能体一起,直到评估者表示输出符合特定标准。
并行运行多个智能体:例如,通过Python原语如
asyncio.gather。当有多个相互独立的任务时,这样做可以提高速度。
我们在examples/agent_patterns中有许多示例。
12. 模型
Agents SDK 原生支持两种 OpenAI 模型调用方式:
推荐方案
OpenAIResponsesModel- 通过全新的 Responses API 调用 OpenAI 接口传统方案
OpenAIChatCompletionsModel- 使用标准的 Chat Completions API 调用 OpenAI 接口
12.1 混合和匹配模型
在单个工作流中,您可能希望为每个智能体使用不同的模型。例如,您可以使用一个较小、较快的模型进行分诊,同时使用一个较大、更强大的模型处理复杂任务。在配置智能体时,您可以通过以下方式选择特定模型:
传递 OpenAI 模型的名称。
传递任意模型名称 + 一个可以将该名称映射到模型实例的 ModelProvider。
直接提供模型实现。
Note
虽然我们的 SDK 支持 OpenAIResponsesModel 和 OpenAIChatCompletionsModel 两种形状,但我们建议每个工作流程使用单一模型形状,因为这两种形状支持不同的功能和工具。如果您的工作流程需要混合和匹配模型形状,请确保您使用的所有功能在两者中均可用。
xxxxxxxxxx301from agents import Agent, Runner, AsyncOpenAI, OpenAIChatCompletionsModel2import asyncio3
4spanish_agent = Agent(5 name="Spanish agent",6 instructions="You only speak Spanish.",7 # 直接设置 OpenAI 模型的名称。8 model="o3-mini", 9)10
11english_agent = Agent(12 name="English agent",13 instructions="You only speak English",14 # 提供模型实现。15 model=OpenAIChatCompletionsModel( 16 model="gpt-4o",17 openai_client=AsyncOpenAI()18 ),19)20
21triage_agent = Agent(22 name="Triage agent",23 instructions="Handoff to the appropriate agent based on the language of the request.",24 handoffs=[spanish_agent, english_agent],25 model="gpt-3.5-turbo",26)27
28async def main():29 result = await Runner.run(triage_agent, input="Hola, ¿cómo estás?")30 print(result.final_output)当您希望进一步配置智能体使用的模型时,可以传递 ModelSettings,它提供了可选的模型配置参数,例如温度。
xxxxxxxxxx81from agents import Agent, ModelSettings2
3english_agent = Agent(4 name="English agent",5 instructions="You only speak English",6 model="gpt-4o",7 model_settings=ModelSettings(temperature=0.1),8)12.2 使用其他 LLM 提供商
您可以通过三种方式使用其他 LLM 提供商(参考示例:examples/model_providers):
set_default_openai_client在您希望全局使用 AsyncOpenAI 实例作为 LLM 客户端的情况下非常有用。这适用于 LLM 提供商具有与 OpenAI 兼容的 API 端点的情况,您可以设置base_url和api_key。请参见examples/model_providers/custom_example_global.py中的可配置示例。ModelProvider位于Runner.run级别。这样您可以指定“在此运行中为所有智能体使用自定义模型提供商”。请参见examples/model_providers/custom_example_provider.py中的可配置示例。Agent.model允许您在特定的智能体实例上指定模型。这使您能够为不同的智能体混合和匹配不同的提供商。请参见examples/model_providers/custom_example_agent.py中的可配置示例。
在您没有来自 platform.openai.com 的 API 密钥的情况下,我们建议通过 set_tracing_disabled() 禁用追踪,或设置不同的追踪处理器。
Note
在这些示例中,我们使用 Chat Completions API/模型,因为大多数 LLM 提供商尚不支持 Responses API。如果您的 LLM 提供商支持该 API,我们建议使用 Responses。
12.3 使用其他 LLM 提供商时的常见问题
12.3.1 追踪客户端错误 401
如果您遇到与追踪相关的错误,这是因为追踪信息被上传到 OpenAI 服务器,而您没有 OpenAI API 密钥。您有三种解决方案:
完全禁用追踪:
set_tracing_disabled(True)。为追踪设置 OpenAI 密钥:
set_tracing_export_api_key(...)。此 API 密钥仅用于上传追踪信息,必须来自 platform.openai.com。使用非 OpenAI 的追踪处理器。请参见追踪文档。
12.3.2 Responses API 支持
SDK 默认使用 Responses API,但大多数其他 LLM 提供商尚不支持它。您可能会看到 404 或类似的问题。要解决此问题,您有两种选择:
调用
set_default_openai_api("chat_completions")。如果您通过环境变量设置了OPENAI_API_KEY和OPENAI_BASE_URL,此方法有效。使用
OpenAIChatCompletionsModel。这里有示例。
12.3.3 结构化输出支持
一些模型提供商不支持结构化输出。这有时会导致类似以下的错误:
xxxxxxxxxx11BadRequestError: Error code: 400 - {'error': {'message': "'response_format.type' : value is not one of the allowed values ['text','json_object']", 'type': 'invalid_request_error'}}这是某些模型提供商的一个局限性——它们支持 JSON 输出,但不允许您指定用于输出的 json_schema。我们正在努力解决此问题,但建议依赖那些确实支持 JSON schema 输出的提供商,因为否则您的应用程序可能会因格式错误的 JSON 而频繁崩溃。
12.4 OpenRouter配置
xxxxxxxxxx51export EXAMPLE_BASE_URL=https://openrouter.ai/api/v12export EXAMPLE_API_KEY=<OPENROUTER_API_KEY>3export EXAMPLE_MODEL_NAME=deepseek/deepseek-r1:free4export OPENAI_API_KEY=<OPENROUTER_API_KEY>5printenvEXAMPLE_API_KEY 从 https://openrouter.ai/settings/keys 创建。
EXAMPLE_MODEL_NAME 从各个模型的API里查看,如 https://openrouter.ai/deepseek/deepseek-r1:free/api
OPENAI_API_KEY 从 https://platform.openai.com/api-keys 创建,以支持追踪器。
12.5 通过 LiteLLM 使用任何模型
pip install "openai-agents[litellm]"
LiteLLM 集成目前处于测试阶段。如果发现任何问题,请通过 GitHub 提交问题,我们会尽快修复。
我们添加了 LiteLLM 集成,以便您在 Agents SDK 中通过单一接口使用任何 AI 模型。
13. 配置 SDK
1. API 密钥和客户端
默认情况下,SDK 在导入时会查找 OPENAI_API_KEY 环境变量以进行 LLM 请求和跟踪。如果您无法在应用启动之前设置该环境变量,可以使用 set_default_openai_key() 函数来设置密钥。
1from agents import set_default_openai_key2set_default_openai_key("sk-...")2. 追踪器
跟踪默认是启用的。它默认使用上述部分中的 OpenAI API 密钥(即环境变量或您设置的默认密钥)。您可以通过使用 set_tracing_export_api_key 函数来专门设置用于跟踪的 API 密钥。您也可以通过使用 set_tracing_disabled() 函数完全禁用跟踪。
3. 调试日志
SDK 有两个 Python 日志记录器,但没有设置任何处理器。默认情况下,这意味着警告和错误会发送到stdout,而其他日志则被抑制。
要启用详细日志记录,请使用 enable_verbose_stdout_logging() 函数。
您也可以通过添加处理器、过滤器、格式化器等来自定义日志。您可以在 Python 日志指南中了解更多信息。
4. 日志中的敏感数据
某些日志可能包含敏感数据(例如用户数据)。如果您希望禁用这些数据的记录,请设置以下环境变量。
要禁用 LLM 输入和输出的日志记录:
11export OPENAI_AGENTS_DONT_LOG_MODEL_DATA=1要禁用工具输入和输出的日志记录:
xxxxxxxxxx11export OPENAI_AGENTS_DONT_LOG_TOOL_DATA=114. 可视化智能体
智能体可视化允许您使用 Graphviz 生成智能体及其关系的结构化图形表示。这对于理解智能体、工具和交接在应用程序中的交互非常有用。
1. 安装
安装可选的 viz 依赖组:pip install "openai-agents[viz]"
2. 生成图形
您可以使用 draw_graph 函数生成智能体可视图。此函数创建一个有向图,其中:
智能体表示为黄色框。
工具表示为绿色椭圆。
交接表示为从一个智能体到另一个智能体的有向边。
xxxxxxxxxx51from agents.extensions.visualization import draw_graph2...3draw_graph(triage_agent) # 默认内嵌显示4draw_graph(triage_agent).view() # 在单独的窗口中显示5draw_graph(triage_agent, filename="agent_graph") # 生成 agent_graph.png 文件,保存在当前工作目录15. 语音智能体
1. 安装
从 SDK 中安装可选的语音依赖项:pip install 'openai-agents[voice]'