DDPM介绍
(余济闻师弟 研究领域AIGC-related Applications & Generation Models)
1-0 前置知识
Markov:当前位置的概率只会受前一时刻概率影响
正态分布(高斯分布)叠加性
贝叶斯
给定条件C下的贝叶斯
1-1 概述
扩散模型相比GAN的优势是:训练难度(调参)、训练的稳定性、损失函数的简易程度(损失的指向性、可观测性)等方面。
1-2 扩散阶段
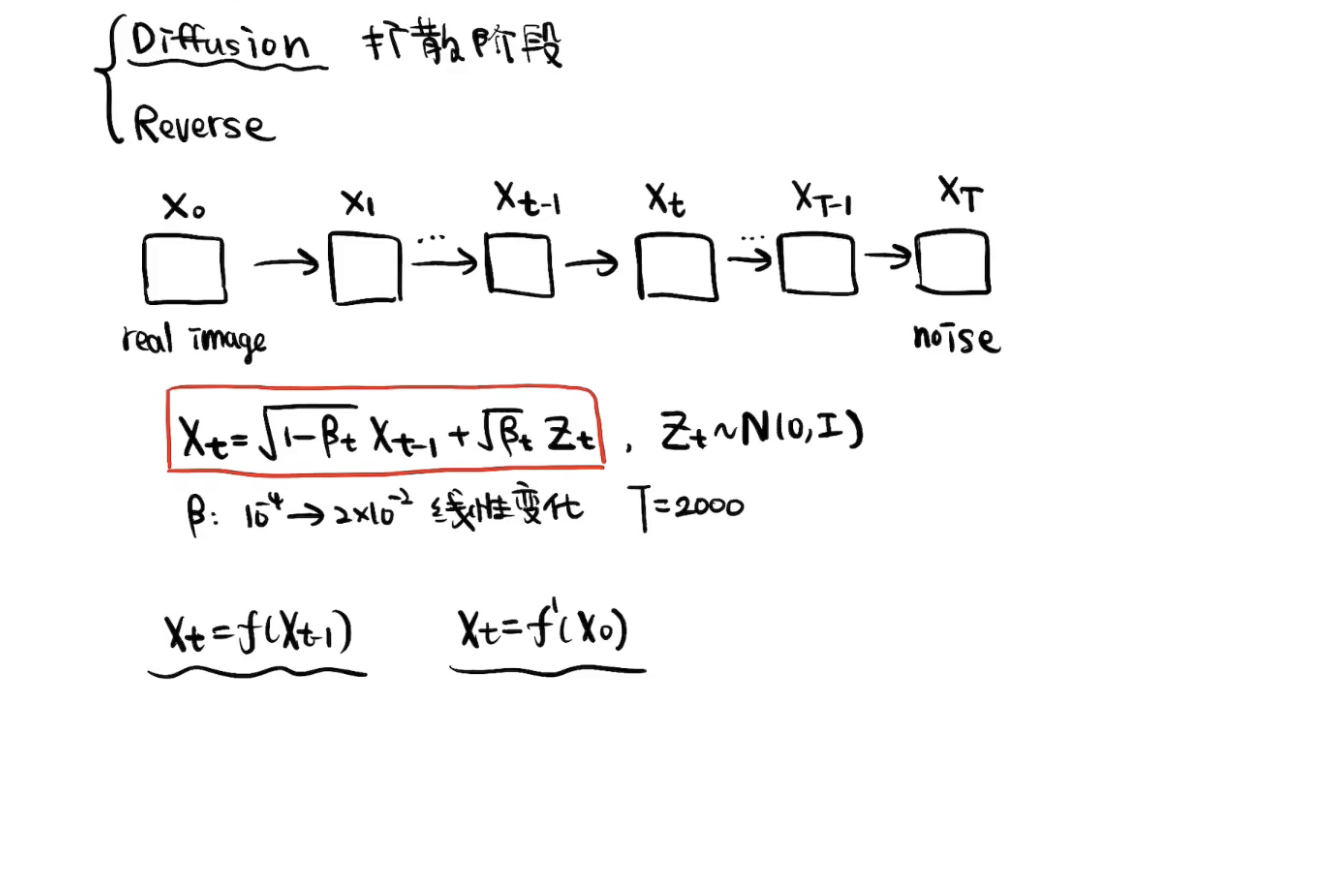
首先,
可想而知,
T也要足够大,才能得到完全的噪声图。
构造

通过公式代入,推导一次
Important
核心公式
,而 是完全的噪声图。所以,实际上我们 的设计和 的选择需要保证 。
逆过程再通过神经网络将噪声
但实际推理时,真实的reverse过程没法这么做,因为从完全的噪声图直接得到
重建的过程是一步一步推的,效果比较好。
1-3 重建阶段(上)
前面知道,重建的公式是:
能估计噪声
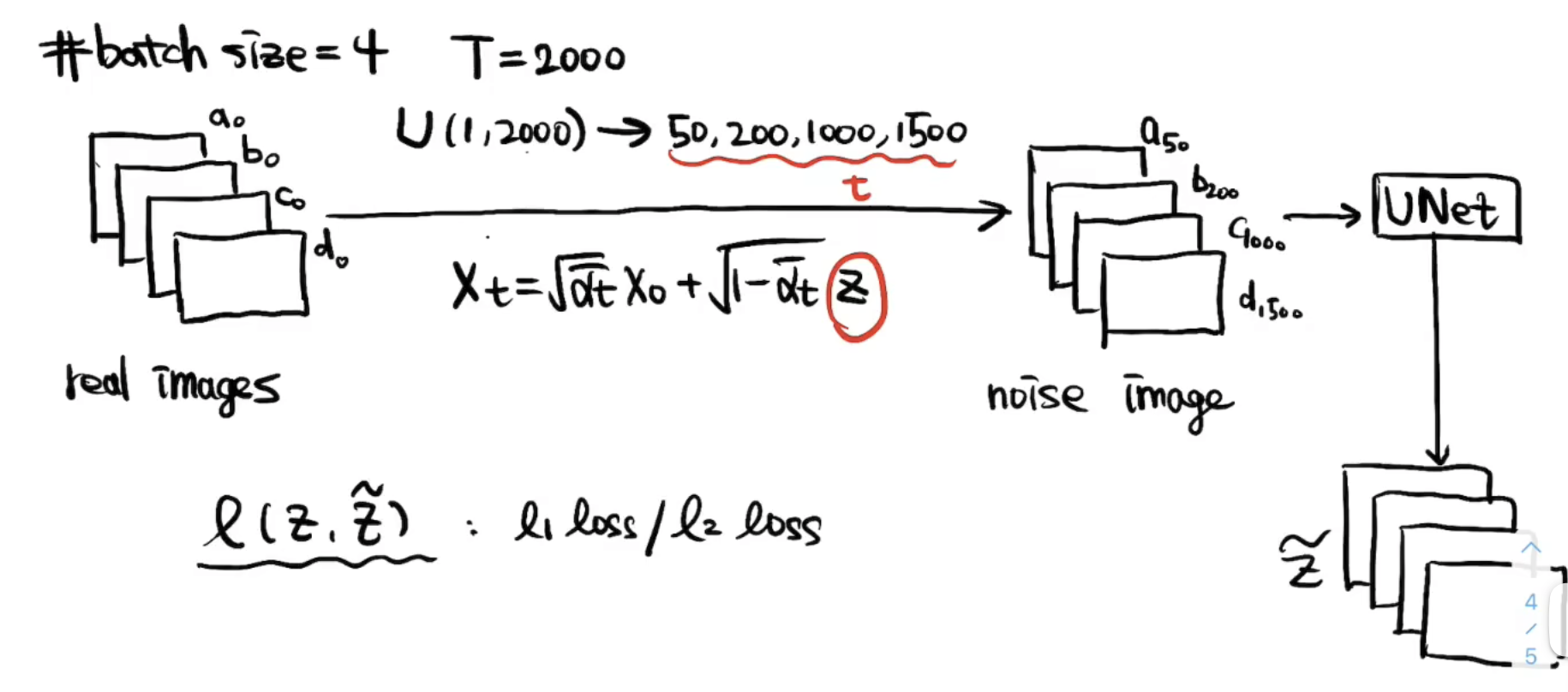
但是一步到位的重建的效果会差、很模糊。我们需要得到一步一步重建的公式:
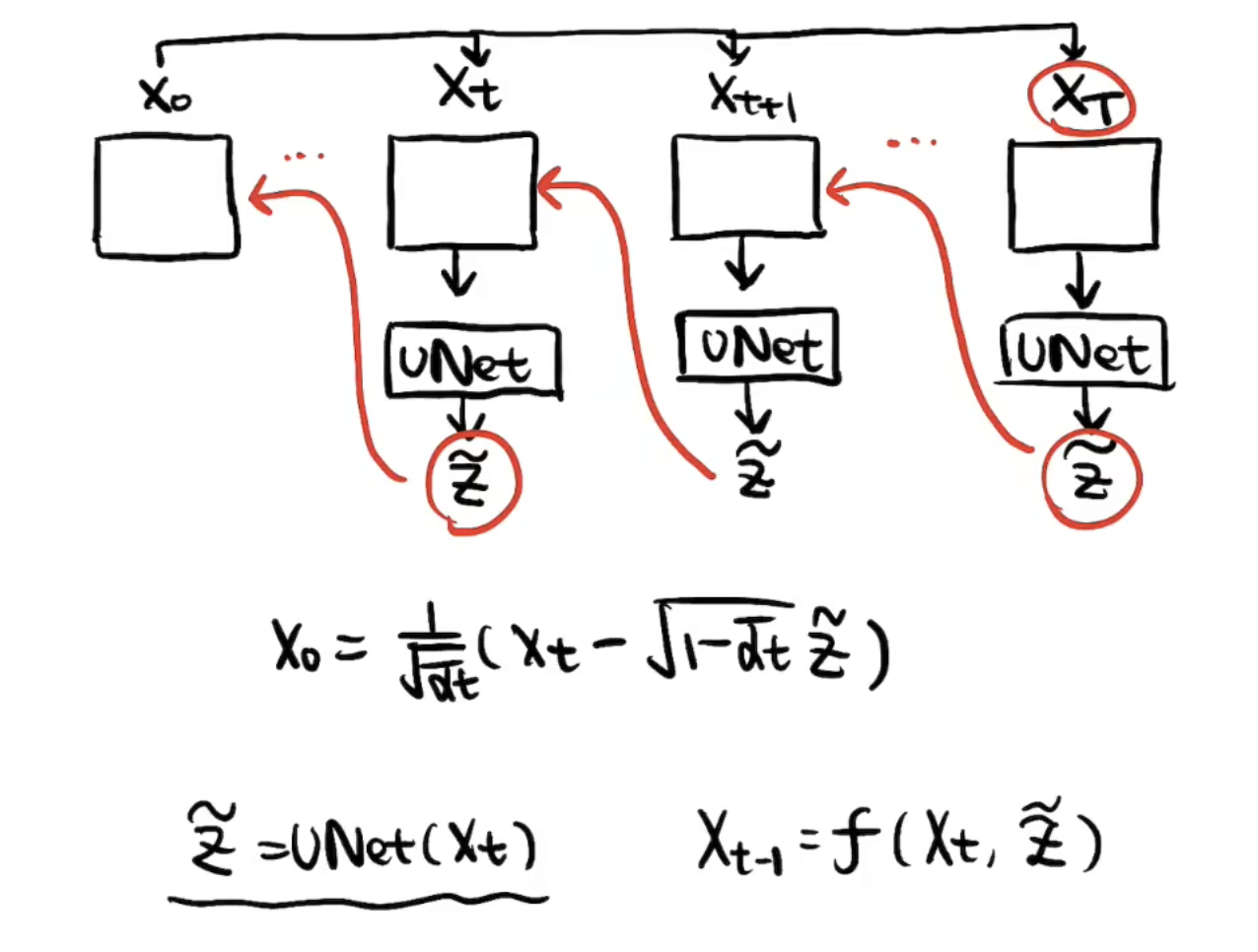
1-4 重建阶段(下)
上面提到我们训练了一个UNet可以将加的噪声采样估计出来。写得再准确一点呢,这个UNet的输入还有t,因为不同的
虽然两个变量可以逆变换,
但可能因为这里的
已知
让我们推一下:
这里
可以写为 ,是因为马尔可夫性质, 时刻只和 有关。
我们最希望构造出
其中
我们可以发现方差实际是由
、 组合而来,所以方差是确定的
由于
前面是为了以示区分,我们后面就将
简称
我们发现均值经过推导可以得到
和 的一个线性组合,一个比较简洁的形式。
总结一下,
即
方差的部分实际上是从标准正态分布采样的
最后
到 这步是不加后面一项噪声的。前面的
Tips:每一次
到 的去噪过程,还要再加一个新的噪声。这也是希望在它整个reverse过程中增加一些不确定性。实际上整个reverse过程也是想模拟一个分子热运动的布朗运动的过程:每一步既有确定性的部分,也有随机的扰动。 Q:为什么UNet预测噪声,而不是直接预测
一方面UNet预测噪声比预测图像更容易,另一方面如果是预测图像就形成了Deterministic的过程,失去多样性,最后一方面,论文将变分下界(Variational LB)作为优化目标。
1-5 整理总结
1.Diffusion(扩散阶段)
都是我们预先设定好的数值, 是我们从标准正态分布里采样的一个噪声。然后由于一步一步加噪不够高效,我们经过一番推导得到从 直接推任意 的退化公式。然后 本身也可以写成正态分布。
2.Reverse(重建阶段)
推导过程的前置知识
,也属于一种重参数技巧。 先验 & 后验,已知 & 未知 & 估计。
越小, (对 的估计)是越来越准的。
和 加权, 的权重越来越小, 的估计越来越准,其权重也越来越大。 可以把扩散过程理解为
, , ,..., 的一个加权,只不过 这个完全的噪声,它的权重非常小。

这里添加的扰动
, 只是适合采用的 的上界,实际小一点,极端来说一直为 不扰动也是可以的。
以上的流程和公式已经比较详尽了,足以手撸DDPM的训练代码。
1-6 代码实现
Note
只讲关键部分的代码实现,可以一定程度上减轻复现或者读懂代码的难度。
比较简单的玩具代码:https://github.com/abarankab/DDPM
比较实用的代码:https://github.com/Janspiry/Image-Super-Resolution-via-Iterative-Refinement
扩散模型实际的代码实现非常简单,进而会让人感叹为什么这样一个简单的设计能够达到这么好的生成效果。
为了复现DDPM,我们需要考虑哪些细节问题?
(1)alpha、beta这些预先定义好的参数怎么获得?
https://github.com/abarankab/DDPM/blob/main/ddpm/diffusion.py
31# 这个函数提供betas2def generate_linear_schedule(T, low, high):3 return np.linspace(low, high, T)221# $alpha_t$2alphas = 1.0 - betas3# $\bar{\alpha}_t$4alphas_cumprod = np.cumprod(alphas) 5'''6partial(偏函数):把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单7'''8# 定义一个函数将任何的numpy array转换为pytorch tensor9to_torch = partial(torch.tensor, dtype=torch.float32)10
11# 接下来将各种公式里用到的各种alpha、beta相关的表达式保存起来12self.register_buffer("betas", to_torch(betas))13self.register_buffer("alphas", to_torch(alphas))14self.register_buffer("alphas_cumprod", to_torch(alphas_cumprod))15
16self.register_buffer("sqrt_alphas_cumprod", to_torch(np.sqrt(alphas_cumprod)))17self.register_buffer("sqrt_one_minus_alphas_cumprod", to_torch(np.sqrt(1 - alphas_cumprod)))18self.register_buffer("reciprocal_sqrt_alphas", to_torch(np.sqrt(1 / alphas)))19
20self.register_buffer("remove_noise_coeff", to_torch(betas / np.sqrt(1 - alphas_cumprod)))21self.register_buffer("sigma", to_torch(np.sqrt(betas)))22# 实际需要用的时候,用t对保存的向量进行索引就可以了(2)训练过程?
231def get_losses(self, x, t, y):2 # 得到标准正态分布噪声Z3 noise = torch.randn_like(x)4 # 调用一步加噪的公式,得到X_t5 perturbed_x = self.perturb_x(x, t, noise)6 # 从X_t, t预测噪声7 estimated_noise = self.model(perturbed_x, t, y)8
9 if self.loss_type == "l1":10 loss = F.l1_loss(estimated_noise, noise)11 elif self.loss_type == "l2":12 loss = F.mse_loss(estimated_noise, noise)13
14 return loss15
16 def forward(self, x, y=None):17 # 输入一个batch的干净图x18 b, c, h, w = x.shape19 device = x.device20 # 得到这个batch的t21 t = torch.randint(0, self.num_timesteps, (b,), device=device)22 return self.get_losses(x, t, y)23# 经过训练得到一个条件去噪网络(这里是UNet)Tip
在这套代码展开的细节中,运用了很多python的实用的语法。
(3)推理过程?
281.no_grad()2def remove_noise(self, x, t, y, use_ema=True):3 if use_ema:4 return (5 (x - extract(self.remove_noise_coeff, t, x.shape) * self.ema_model(x, t, y)) *6 extract(self.reciprocal_sqrt_alphas, t, x.shape)7 )8 else:9 return (10 (x - extract(self.remove_noise_coeff, t, x.shape) * self.model(x, t, y)) *11 extract(self.reciprocal_sqrt_alphas, t, x.shape)12 )13
14.no_grad()15def sample(self, batch_size, device, y=None, use_ema=True):16 if y is not None and batch_size != len(y):17 raise ValueError("sample batch size different from length of given y")18 # X_T19 x = torch.randn(batch_size, self.img_channels, *self.img_size, device=device)20 # loop(X_t → X_{t-1})21 for t in range(self.num_timesteps - 1, -1, -1):22 t_batch = torch.tensor([t], device=device).repeat(batch_size)23 x = self.remove_noise(x, t_batch, y, use_ema)24 # 最后一步 X_1 → X_0 是不需要加扰动噪声的25 if t > 0:26 x += extract(self.sigma, t_batch, x.shape) * torch.randn_like(x)27
28 return x.cpu().detach()前面提到扰动的噪声,实际比上界小一点也是可以的。
,所以我们将 可以简化为 使用,使得代码也更为简洁。
(4)UNet的结构?
https://github.com/abarankab/DDPM/blob/main/ddpm/unet.py
191# 一个非常典型的UNet结构2x = self.init_conv(x)3
4skips = [x]5
6for layer in self.downs:7 x = layer(x, time_emb, y)8 skips.append(x)9
10for layer in self.mid:11 x = layer(x, time_emb, y)12
13for layer in self.ups:14 if isinstance(layer, ResidualBlock):15 x = torch.cat([x, skips.pop()], dim=1)16 x = layer(x, time_emb, y)17
18x = self.activation(self.out_norm(x))19x = self.out_conv(x)关键:time_emb是怎么得到的,是怎么作为条件输入的。
131# 1. 怎么得到的:2self.time_mlp = nn.Sequential(3 PositionalEmbedding(base_channels, time_emb_scale),4 nn.Linear(base_channels, time_emb_dim),5 nn.SiLU(),6 nn.Linear(time_emb_dim, time_emb_dim),7 ) if time_emb_dim is not None else None8
9time_emb = self.time_mlp(time)10# 2. 怎么作为条件的:11self.time_bias = nn.Linear(time_emb_dim, out_channels)12out += self.time_bias(self.activation(time_emb))[:, :, None, None]13# 很类似transformer里的位置编码,只不过又增加了点复杂度(activation和time_bias)x → norm/act/conv → + time_emb → norm/act/conv + shortcut → attention → out (这算是一种比较简单的调控,实际上你可以想到任何条件网络的控制方式都有可能能够用在这里)
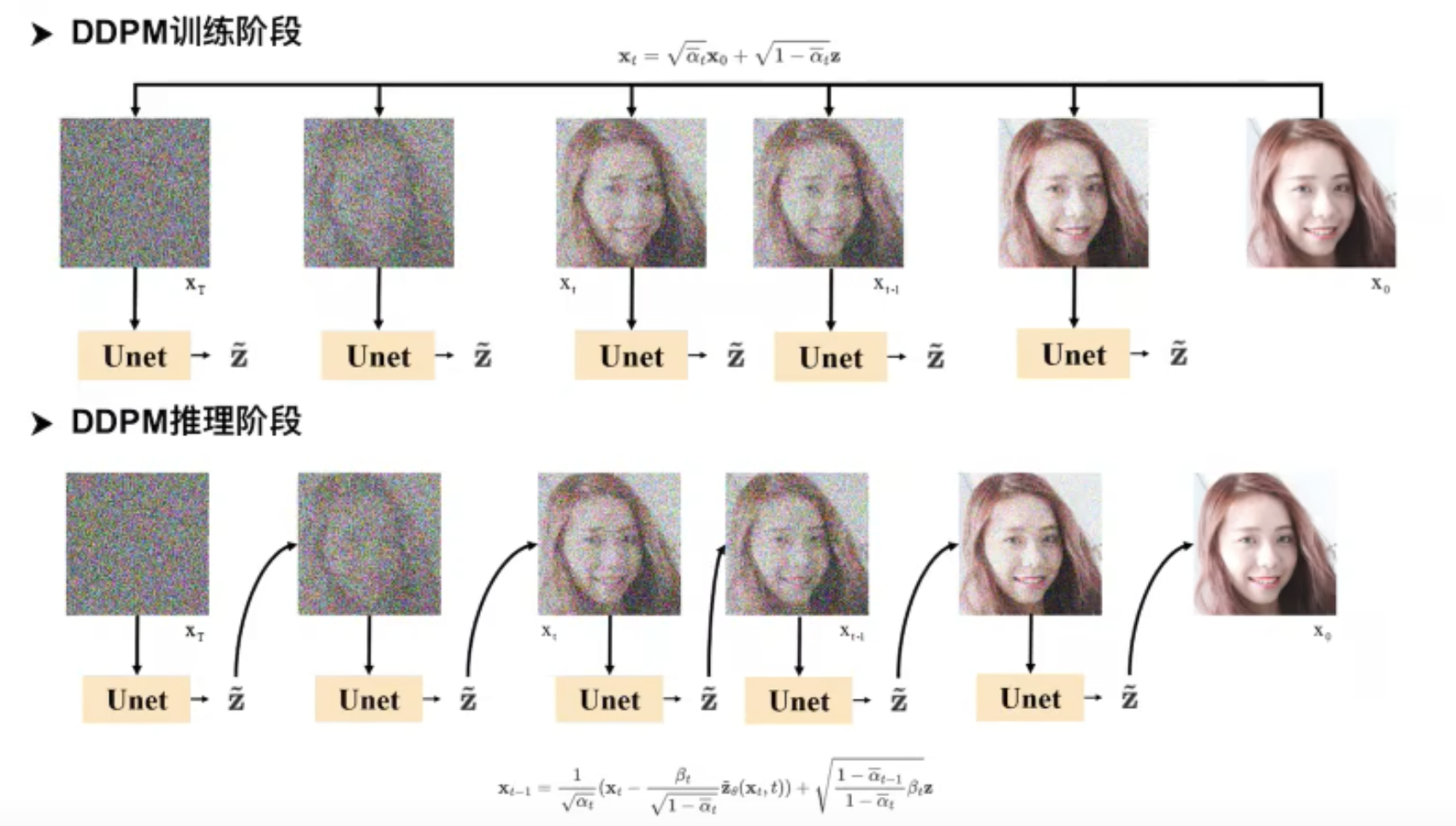
DDPM的应用
DDPM的流程图:
2-1 SR3
Image Super-Resolution via Iterative Refinement(https://ar5iv.labs.arxiv.org/html/2104.07636)
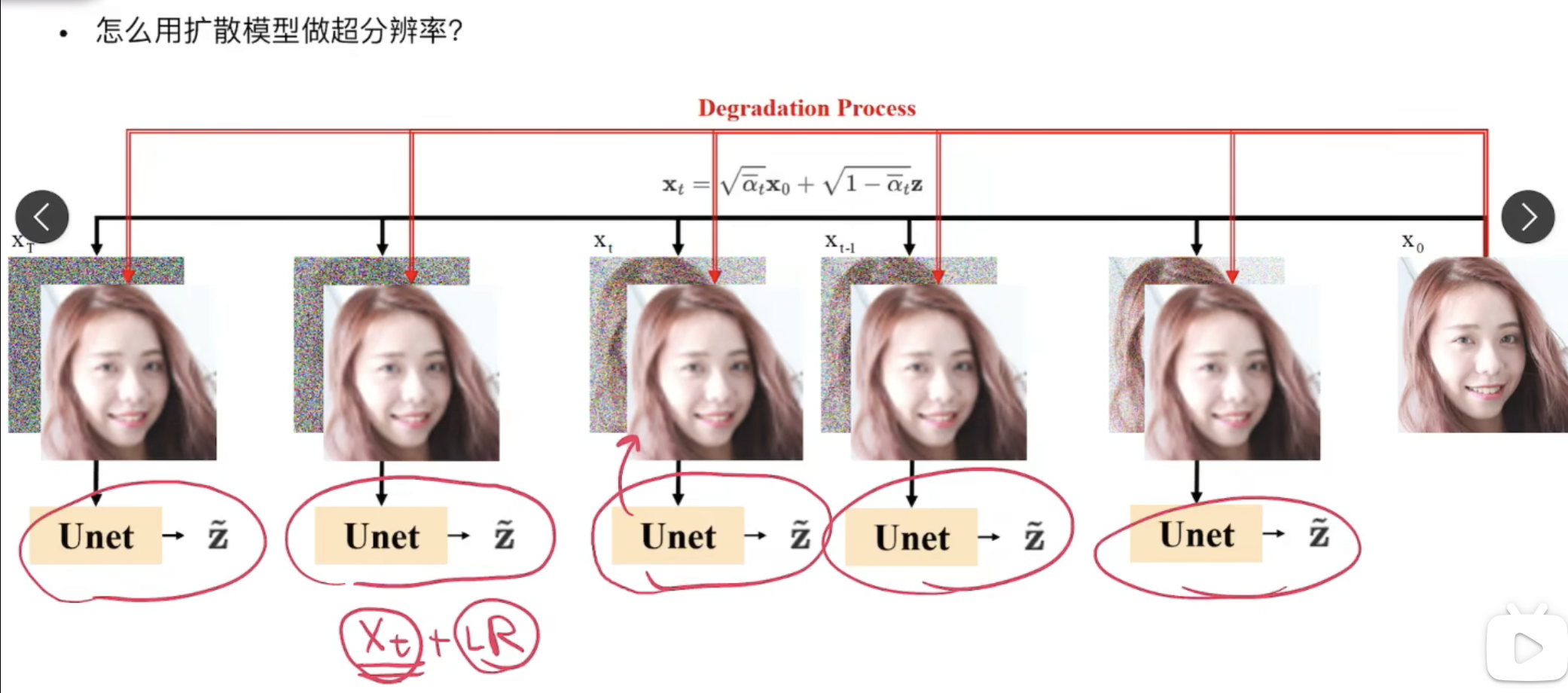
相对DDPM的改动:
改动1:将LR作为condition,与噪声图concat之后送给UNet重建,即UNet现在是输入6通道,输出3通道
改动2:不再直接取
改动3:不再输入
个人解读:
UNet处似乎可以改为pixel-shuffle减少复杂度
之前有文章认为与其隐晦地给一个
,不如将噪声强度 作为条件。 改动2是为改动3作铺垫的,二者连用。从均匀分布
里取噪声强度,它更连续,也给后面我们为了推理加速设定新的 提供了支持。
改动2是为可以任意改变采样的步数铺路,不然UNet只见过离散的条件。
对于 np.linspace(low, high, T),假设训练时 low=1e-4, high=2e-2, T=2000,推理时 我们可以设定 新的 low=1e-4, high=0.1, T=100,只要最后满足T=2000到T=100推理速度快了20倍。
2-2 deblur
Deblurring via Stochastic Refinement(https://openaccess.thecvf.com/content/CVPR2022/papers/Whang_Deblurring_via_Stochastic_Refinement_CVPR_2022_paper.pdf)
Stochastic Refinement 就是指的扩散模型
提出问题:目前的图像去模糊问题主要是deterministic的方法,重建的视觉质量不好
提出解决方案:1. 提出一个新框架,基于条件扩散模型 2. 同时也提出一个有效的predict-and-refine的方法,并给出扩散模型在PD曲线上遍历的方法
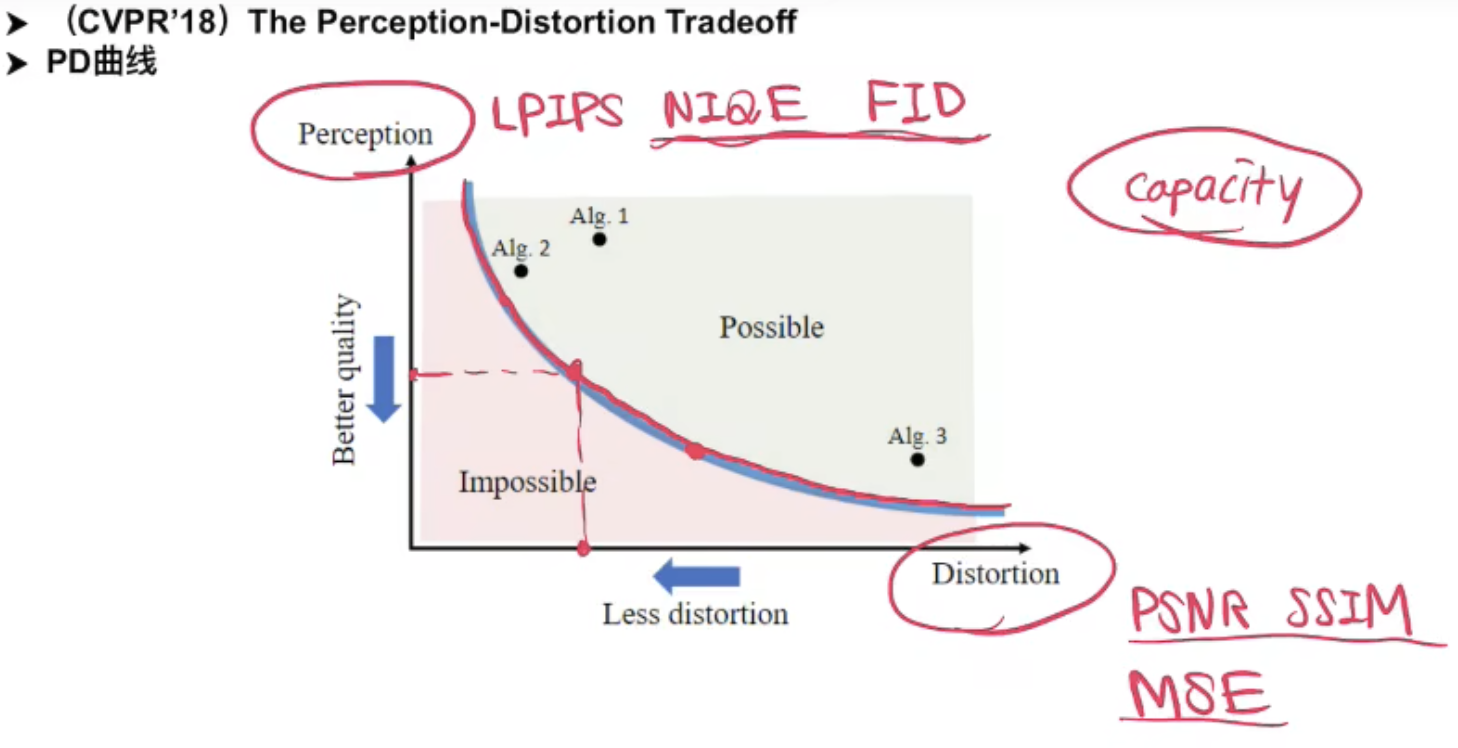
以前的经验和分析得出,在模型能力(size)一定的情况下,它的Perception和Distortion的指标是有trade-off的。
改进1:predict and refine策略,实际上就是扩散模型的
由于学残差相对容易,Denoiser(UNet)可以设计得更轻量。
这篇文章补充材料就提到initial predictor和denoiser结构是一样的,只是base channel不一样,前者是64,后者是32。参数量上前者约26M,后者约7M。
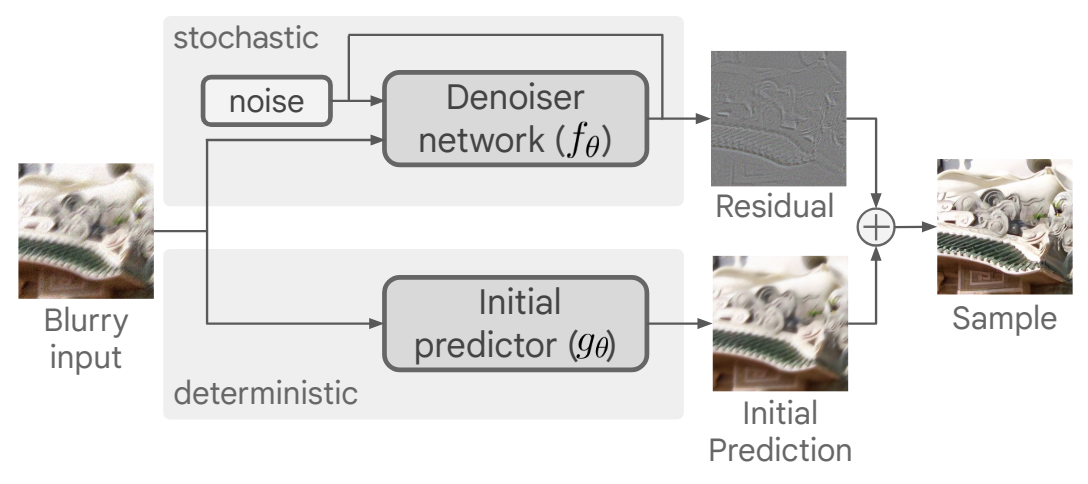
改进2:Sample averaging:由于每一次的采样具有随机性,所以可以多重建几次,然后取平均。这是一种比较简单的self-ensemble的方法。
改进3:Traversing the PD curve:采样的步数越多,则主观质量越好,反之则客观质量越好。

改进4:训练时使用小patch,测试时用整张图。很多low-level模型训练都是这么做。
2-3 DDIM
Denoising Diffusion Implicit Models(https://ar5iv.labs.arxiv.org/html/2010.02502)
回顾DDPM(去噪扩散概率模型):
在 DDPM 中,生成过程被定义为马尔可夫扩散过程的反向过程,在逆向采样过程的每一步,模型预测噪声。

DDIM(去噪扩散隐式模型):
DDIM 的作者发现,扩散过程并不是必须遵循马尔科夫链, 在之后的基于分数的扩散模型以及基于随机微分等式的理论都有相同的结论。 基于此,DDIM 的作者重新定义了扩散过程和逆过程,并提出了一种新的采样技巧, 可以大幅减少采样的步骤,极大的提高了图像生成的效率,代价是牺牲了一定的多样性, 图像质量略微下降,但在可接受的范围内。
去马尔可夫化,DDIM用待定系数法推导:
回到
由于不是马尔可夫过程,等式右边
, , 理论上我们都不知道,左边分布的解的可能性会更多。但由于DDIM只是采样方法,我们用的UNet模型还是DDPM一样的方式训练的,所以 , 需要满足DDPM的公式。 现在仅仅是
是未知的。在DDPM里是转换成了 ,但这个马尔可夫的强假设,并不是必要的,因为训练过程中并没有 到 的加噪。我们不妨使用待定系数法,不限制它的形式。 其实DDIM里前向的增噪过程
也已经和DDPM不一样了,但是因为训练过程中没用到,就没事,只要训练中一步到位加噪的 一致,我们的噪声预测模型就依然是DDPM/DDIM通用的。
假设
待定系数
Important
以下推导中的
设:
(DDIM论文里的
求得:
DDIM仅用待定系数法假设满足
,没有任何其他强假设。推导过程中也没有用到 。 DDIM 可以看做是 DDPM 的扩展, DDPM 是 DDIM 的一个特例
因为DDIM不是马尔可夫假设,所以不需要严格遵守
由于推导中
DDIM推导中的
是待定系数法假设来的,是一个自由随机变量。
如果
如果
作者发现
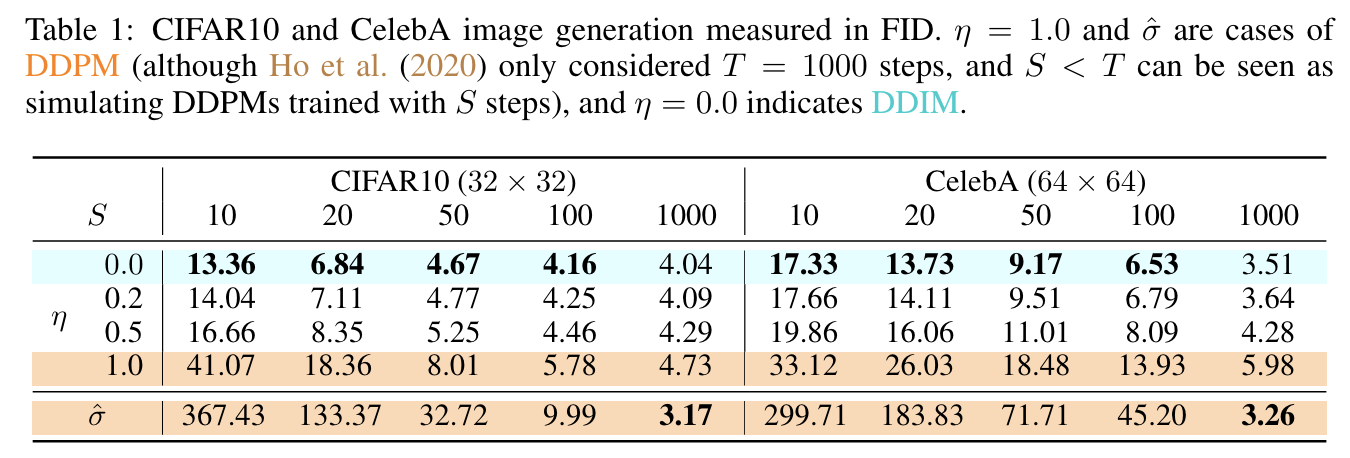
DDIM牺牲了多样性,提升了图片质量。
总结,DDIM特点:多样性↓,速度↑,图像质量↑
在DDIM里,取了
直接分析构造(高视角)
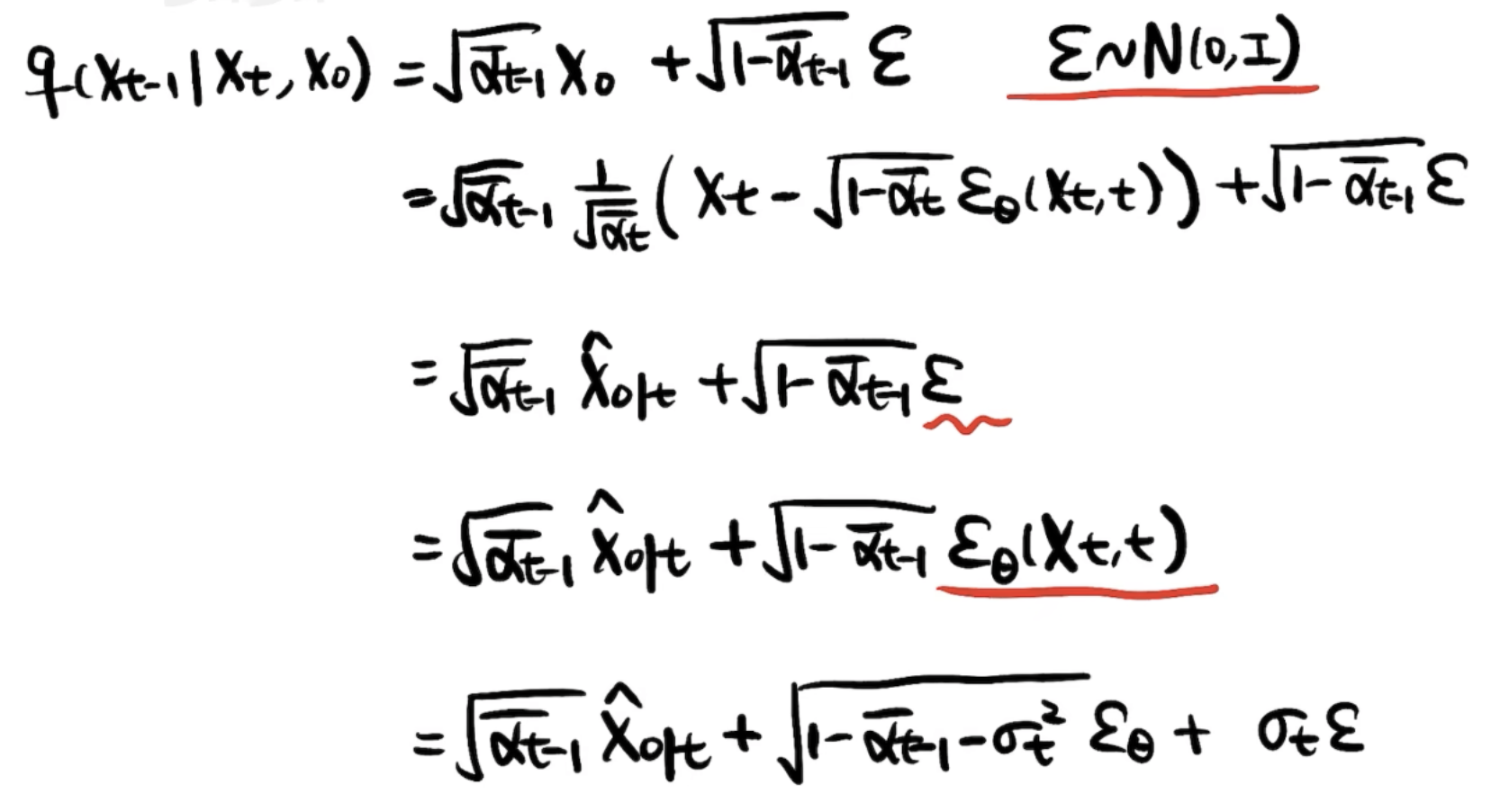
可以看到这每一步都好理解,
前三个等式就是解释训练过程中加噪的方式和UNet学到的去噪能力。
第三个等式到第四个等式的转换(
第五个等式再将噪声拆开,只要满足二者方差相加等于原先的方差。折中回到一个相对比较一般的公式。且当
等式中用特殊代替一般是成立的。而且确定性更强。
2-4 guided-diffusion
Diffusion Models Beat GANs on Image Synthesis (https://proceedings.neurips.cc/paper_files/paper/2021/file/49ad23d1ec9fa4bd8d77d02681df5cfa-Paper.pdf)
扩散模型提出后有两大优势:1.生成效果较好,保真度高,2.生成图像多样性高。但直到guided-diffusion这篇文章发表之前,扩散模型在保真度的指标(FID)上一直没有超过GAN。
改进1:网络结构优化。
改进2:引入classifier guidance的采样方法,分类器做监督。
条件生成既可以使得模型可控,又可以增加保真度(研究conditional GAN的学者发现条件生成可以提高FID)。
不影响训练过程,和DDIM一样,只作为一种采样方式。
设
,再添 的条件。但数学功底够好,可以直接看出得到下面的等式。
如果沿用DDPM的训练,只是在采样阶段使用classifier guidance,有:
Markov
我们继续推:
classifier guidance和classifier-free guidance
其他优秀博客